论文笔记
论文题目Attribute Prototype Network for Zero-Shot Learning (NeurIPS 2020)
摘要
从ZSl研究开始,视觉属性(说的就是Attributes)就被显示出重要的作用。为了更好地从已知类到未知类传递属性知识,我们认为具有属性定位能力的图像特征表示有利于ZSL(原文:image representation with integrated attribute localization ability would be beneficial for zero-shot learning)。为此,我们提出了一种新的零次学习特征表示框架,该框架的特点是只使用class-level的属性学习具有较好区分度的全局性和局部性特征。其中视觉语义嵌入层(visual-semantic embedding)用来学习全局性特征时,局部性的特征是通过一个属性原型网络(attribute prototype network, 这也就是本文的主要创新点)学习,该网络可以同时从中间层特征回归和decorrelates(correlate是相关联的意思,decorrelates我猜测是去除相关联的意思?)属性。实验表明,我们的属性定位能力增强的图像表示在三个数据集中均实现了最好的性能。而且,该模型能够较好的指出与类别属性相关的图像视觉方面的证据,并给出CUB数据集上的一些例子。
当前的现状和需要解决的问题(story line):
-
当前的ZSL方法依赖预训练好的特征,关注与视觉-语义映射关系的学习,而具有属性定位能力的图像特征表示没有被认真考虑过。属性定位能力是指图像特征将属性和图像某个区域的特征相关联的能力。(we refer to the ability of an image representation to localize and associate an image region with a visual attribute as locality) 简单来说就是以前都是利用预训练得到的图像特征学习视觉-语义之间的映射关系,但是并没有仔细考虑对于每一个属性,图像中与其相对应的区域是否能够较好的表示这一属性,起码与属性(如黄色腹部)相对应的区域特征与属性的关联度要比其他地方要高。事实上,人类判别物种时也是先根据自己设定的判别标准也就是一堆属性,查找出相应的区域,然后判别是否符合,如果符合则判别为正,否则为负。 本文要做主要工作就是改善所谓的图像特征的属性定位能力。
-
CNN编码后的图像特征虽然能够反映图像局部信息,但是这种表示不一定较好的符合ZSL的需要。虽然当前的一些ZSL方法使用视觉注意力机制的思想来改善特征的定位能力。但是这种学习方法容易产生偏置,黄冠黄腹在训练集中常常会同时出现(比如黄林莺就同时具备这两个属性),那么在训练的过程中就会产生只要同时出现了以上两种属性很大可能就是黄林莺,那么在预测未知的属性组合时,可能就是黑冠和黄腹作为一对属性出现,就很难很好的应对处理。
综上,作者提出了一种弱监督表征学习框架来增强图像特征的定位能力。
相关工作
-
ZSl
-
原型学习(Prototype learning)
-
Locality and representation learning
模型介绍
下图是本文的模型结构示意图,包括两个部分:Base Module (BaseMod) for global feature learning, Prototype Module (ProtoMod) for local feature learning。
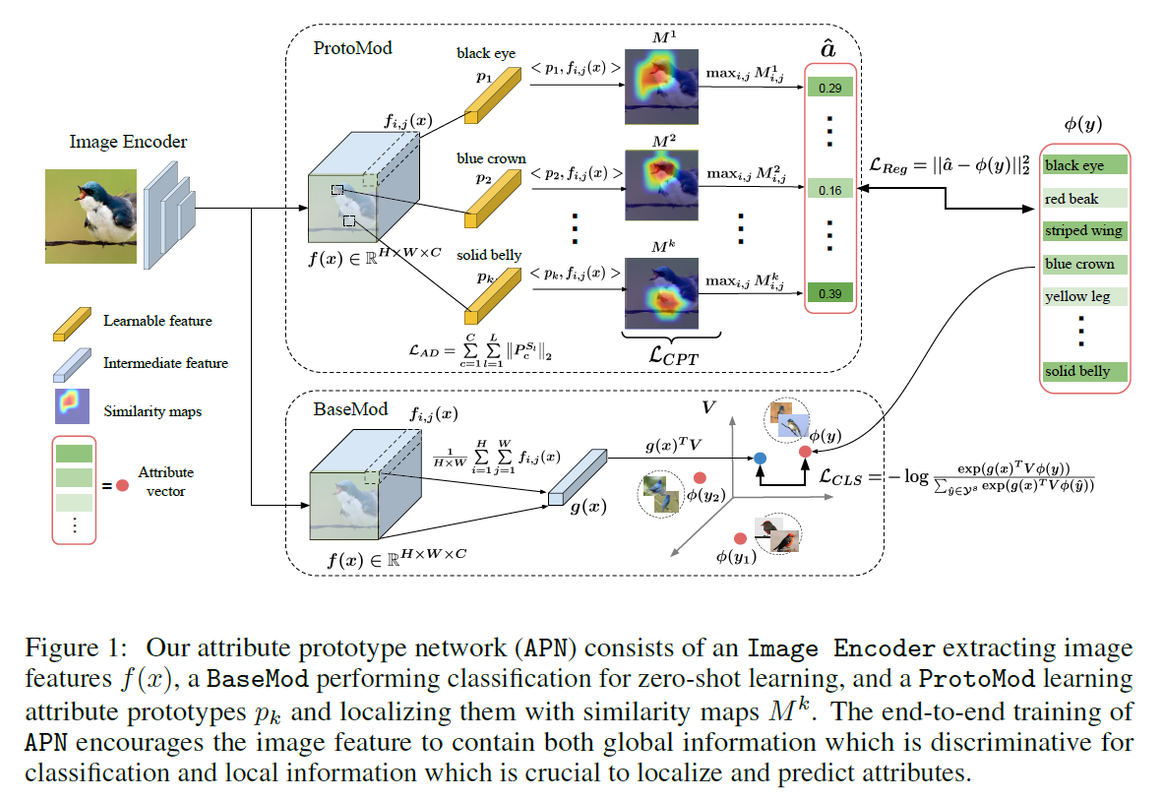
- Base Module (BaseMod) for global feature learning
这部分是根据图像的全局特征嵌入到语属性空间,与其相似度最高的那个属性向量所对应的类别为分类结果。
CNN编码后的特征 $f(x) \in \mathbb{R}^{H \times W \times C}$.
作全局平均池化
\[g(x)=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} f_{i, j}(x)\]池化后的特征$g(x) \in \mathbb{R}^{C}$ 通过一个参数$V \in \mathbb{R}^{C \times K}$再嵌入到属性空间, $\phi(y)$是属性标签.
分类交叉损失函数
\[\mathcal{L}_{C L S}=-\log \frac{\exp \left(g(x)^{T} V \phi(y)\right)}{\sum_{\hat{y} \in \mathcal{Y}^{s}} \exp \left(g(x)^{T} V \phi(\hat{y})\right)}\]在预测的时候计算
\[MAX_{ \hat{y} \in \{ \mathcal{Y^{S}} \cup \mathcal{Y^{U}} \}} g(x)^{T}V \phi(\hat{y})\]其实这部分就是一个分类器,这部分与前面的CNN骨干网络以及后面要讲的Prototype Module共同训练。
- Prototype Module (ProtoMod) for local feature learning
该部分的输入还是之前CNN编码后的特征,目的是将编码的图像特征具有较好的视觉属性定位能力,即对于每个属性,在视觉特征上都有与其相关的局部区域。 首先学习得到一个属性的原型特征 \(P=\{p_k \in \mathbb{R}^{C} \}_{k=1}^{K}\), 然后基于此计算输入的特征图每个区域与属性原型特征的相似度,\(M_{i, j}^{k}=\left\langle p_{k}, f_{i, j}(x)\right\rangle\)从而得到一个属性原型注意力图\(M^{k} \in \mathbb{R}^{H \times W}\),并取最大值作为图像特征对该属性的预测输出值。
\[\hat{a}_{k}=\max _{i, j} M_{i, j}^{k}\]进而可以得到回归预测损失函数
\[\mathcal{L}_{R e g}=\|\hat{a}-\phi(y)\|_{2}^{2}\]此外本文还引入了 Attribute decorrelation loss.
主要是考虑到一些视觉属性同时出现的频率较高,它们之间往往存在相关性,如蓝冠和蓝背。那么,网络可以利用这些相关性作为有用的信号进行偏置性分类判别,而无法识别新类中未知的属性组合。我们提出通过鼓励不相关属性间的特征竞争和相关属性间的特征共享来约束属性原型。
具体做法:
$K$个属性分成$L$个不相交的集合, $S_1, \cdots, S_L$,划分规则是如果两个属性有相似的的语义关系则划分为一个集合或者说一组,比如蓝眼睛和黑眼睛。本文作者直接采用了文献[37,19,29]属性组划分,然后将每个属性集合中的每个属性原型特征拼接为一个矩阵$P^{S_l} \in \mathbb{R}^{C \times |S_l|}$,采用文献[15]的attribute decorrelation (AD) loss样式得到损失函数:
另外作者还加了属性原型注意力图密集度正则化项损失函数:
\[\mathcal{L}_{C P T}=\sum_{k=1}^{K} \sum_{i=1}^{H} \sum_{j=1}^{W} M_{i, j}^{k}\left[(i-\tilde{i})^{2}+(j-\tilde{j})^{2}\right]\]其中\((\tilde{i}, \tilde{j})=\arg \max _{i, j} M_{i, j}^{k}\)就是注意力图的最大值的坐标。这个损失函数强制属性原型只和少量的局部特征相似,从而产生一个紧凑的相似度或者注意力映射关系。
相关文献
ZSL-visual attention:
- Discriminative learning of latent features for zero-shot recognition
- Locality and compositionality in zero-shot learning
- Semantic-guided multi-attentionlocalization for zero-shot learning
[37] C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, The Caltech-UCSD Birds-200-2011 Dataset,Tech. Report CNS-TR-2011-001, California Institute of Technology, 2011.
[19] Christoph H Lampert, Human defined attributes animals with attributes, 2011, http://pub.ist.ac.at/~chl/talks/lampert-vrml2011b.pdf.
[29] Genevieve Patterson, Chen Xu, Hang Su, and James Hays, The sun attribute database: Beyond categories for deeper scene understanding, IJCV 108 (2014).
[15] Dinesh Jayaraman, Fei Sha, and Kristen Grauman, Decorrelating semantic visual attributes by resisting the urge to share, CVPR, 2014.