The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification 论文笔记
该论文收录在TIP2020期刊上
摘要
本文针对细粒度分类任务中具有较强区分性的图像注意力区域获取提出了新的损失函数,该损失函数能够特征能够学习到更加具有区分性的特征表示,同时还能约束各通道关注图像不同的区域特征。提出的损失函数MC-Loss包括两部分:
- a discriminality component
The discriminality component forces all feature channels belonging to the same class to be discriminative, through a novel channel-wise attention mechanism.
- a diversity component
The diversity component additionally constraints channels so that they become mutually exclusive on spatial-wise
通过在数据集CUB-Birds, FGVC-Aircraft, Flowers-102, and Stanford-Cars上的实验验证了该损失函数能够在现有的一般基础网络模型上取得最好的分类效果。
损失函数介绍
总体的损失函数形式:
\[L_{MC}(F)=L_dis(F)- \lambda \times L_{div}(F)\]模型架构如下:
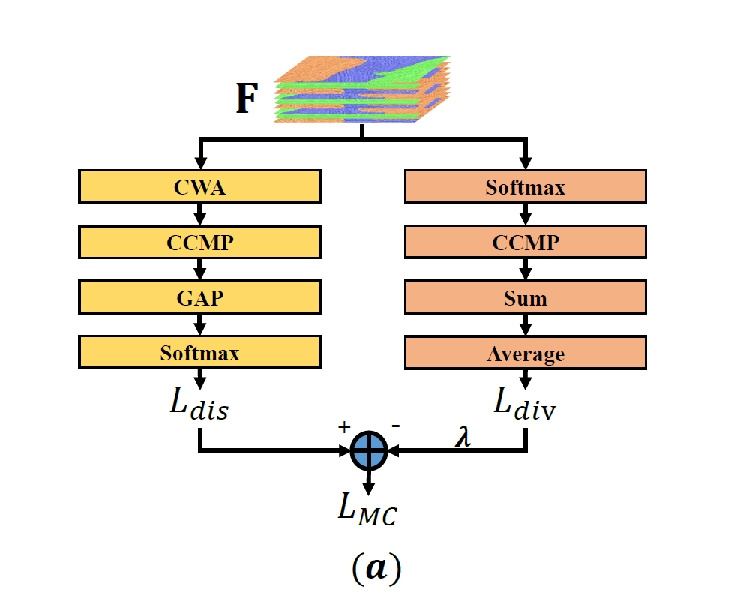
损失函数 $L_{dis}$
\[L_{dis}(\mathbf{F})=L_{C E}({y}, \underbrace{\frac{\left[e^{g\left(\mathbf{F}_{0}\right)}, e^{g\left(F_{1}\right)}, \cdots, e^{g\left(\mathbf{F}_{c-1}\right)}\right]^{\mathrm{T}}}{\sum_{i=0}^{c-1} e^{g\left(F_{i}\right)}}}_{\text {Softmax}}),\]其中
\[g\left(\mathbf{F}_{i}\right)=\underbrace{\frac{1}{W H} \sum_{k=1}^{W H}}_{\text {GAP }} \underbrace{\max _{j=1,2, \cdots, \xi}}_{\text {CCMP }} \underbrace{\left[M_{i} \cdot \mathbf{F}_{i, j, k}\right]}_{\text {CWA }}\]$L_{dis}$ 的计算主要包括CWA(Channel-Wise Attention),CCMP(Cross-Channel Max Pooling),GAP(Global Average Pooling)三步.
-
CWA(Channel-Wise Attention)查看代码发现该步操作实际上就是从每个类别所对应的特征通道中随机选择若干特征图,以进行下一步计算。
-
CCMP(Cross-Channel Max Pooling)由于对于每个类别都有一定的特征通道数目,因此该步是沿着特征通道的方向进行最大化池化,池化后的通道数目等于类别数目。
-
GAP(Global Average Pooling)对每个特征通道进行全局平均池化,得到一个维度等于类别数目的向量,并结合目标类别计算得到损失$L_{dis}$.
该损失主要是通过随机选择特征通道映射到目的标签,使得每个特征通道都尽可能包含区分性特征。
损失函数 $L_{div}$
该损失函数的作用是迫使每个特征通道都尽可能关注图像的不同区域的特征。
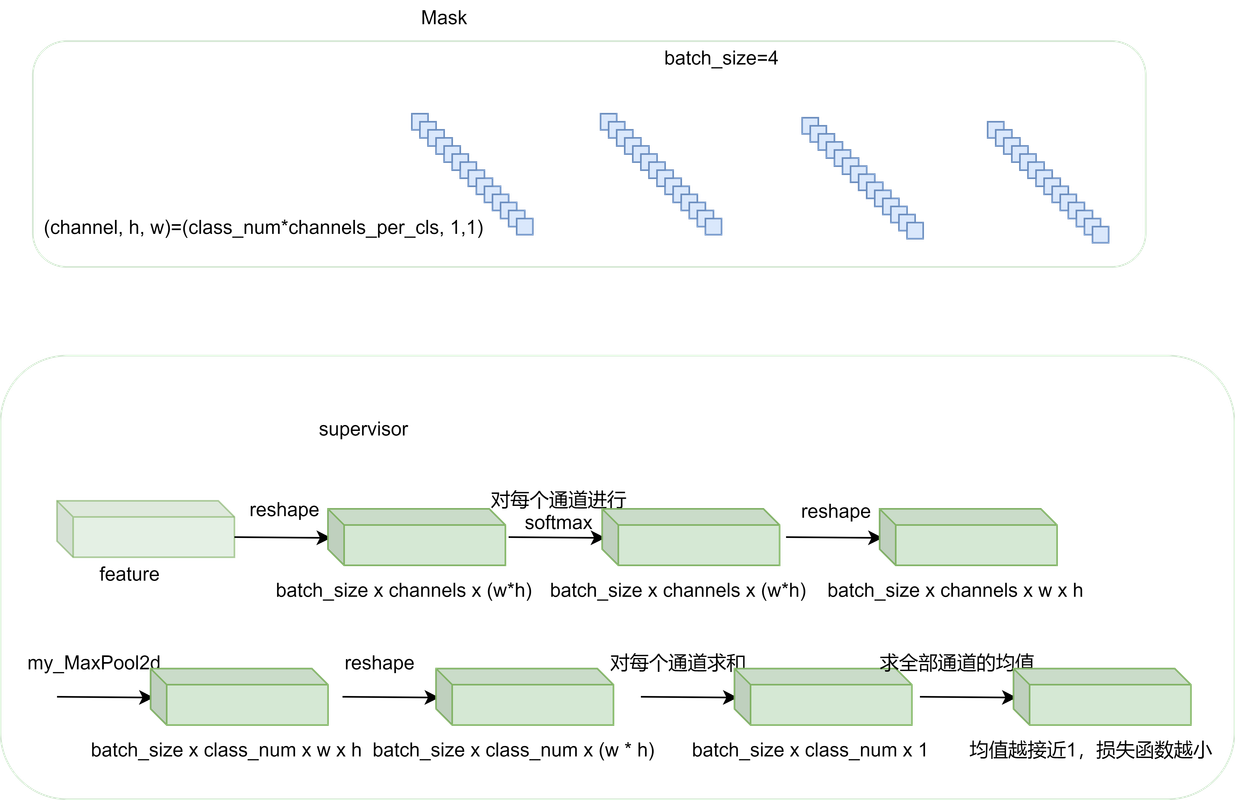
计算过程如上图的右分支,更详细的计算过程如下图所示
实验相关问题
-
由于每个类别对应一定的特征通道数目,也就是说对于不同的数据集可能需要通过
VGG或者Resnet提取的特征通道数不一致,而且与一般的预训练模型不一致,这需要从头训练网络,难度估计不小;但是为了能够使用别人预训练好的网络,作者针对数据集中的不同类别指定不同特征通道数,使得最后全部类别的通道总数目等于人家预训练模型输出的通道数,预训练的VGG16通道数是512,Resnet50是2048。 -
在基础模型上添加不同损失函数后的性能比较