ChengYue's Cat
Simpler is Better: Few-shot Semantic Segmentation with ClassifierWeight Transformer
Simpler is Better: Few-shot Semantic Segmentation with ClassifierWeight Transformer 2021_ICCV
论文简要介绍
- 任务:少样本分割问题
- 贡献:
- 提出了一种新的少样本分割模型训练范式,与以往的同时关注特征提取器和分类器不同,本文将二者分开,并对分类器使用元学习训练策略。
- 提出了一种叫做
Classifier Weight Transformer的自适应分类器,其实就是在qkv的注意力基础上加入了一种所谓的classifier-to-query-image注意力,和Agzsl里的自适应注意力思想基本一样。 - 模型结果基本SOTA.
模型概览
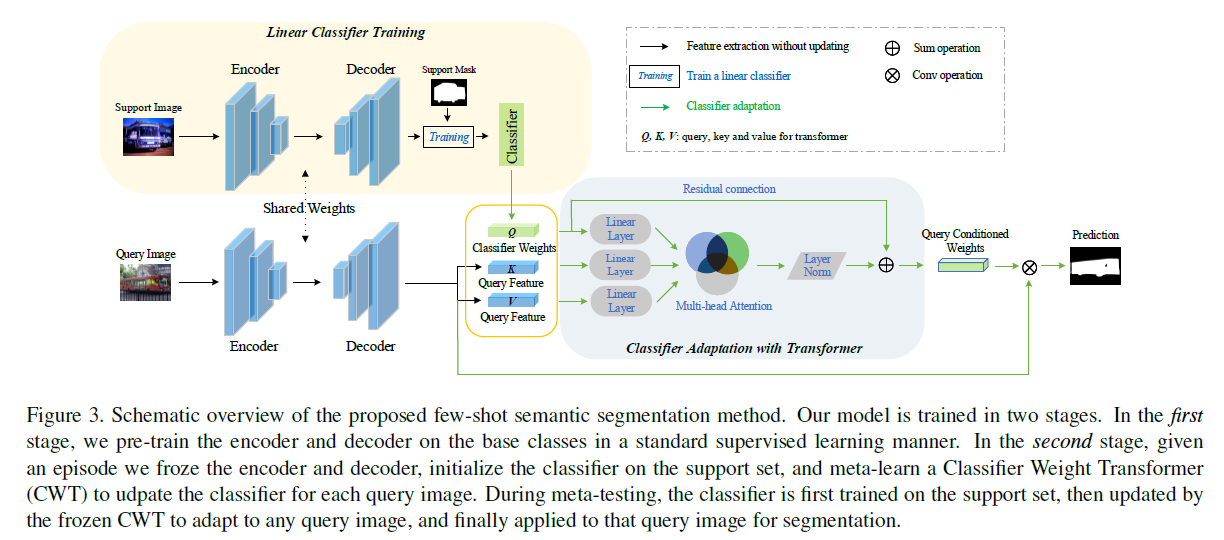
模型包括两个训练阶段:
- 阶段一:预训练特征提取的BackBone,作者使用了两种分别是ResNet50和ResNet101,对应上图的黄色部分,训练后的BackBone参数被固定用于第二阶段特征的提取,而分类器权重则被作为第二阶段
Transformer的Q输入。 - 阶段二:该阶段使用元学习策略训练得到自适应的分类器权重,即
Classifier Adaptation with Transformer. 正如文中说的During episodic training, we aim to learn via our CWT how to adapt the classifier weights to a sampledclass in each episode. 这里的分类器权重 $w \in {2d}$.Transformer的输入是一个元组包括上一阶段的分类器权重 $w$ , 以及query image $F$, 之后$F$即作为 $k$ ,又作为 $v$. 和其它地方使用qkv注意力类似,这里也使用了权重参数 $w_q, w_k, w_v$ 将三个输入映射到 $d_a$维度的空间。之后应用一个自适应注意力
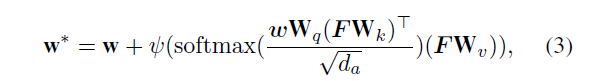
作者说这样做的动机是 The intuition is that, the pairs involving a query image pixel from the new class often enjoy higher similarity than those with background classes except few outlier instances; as a result, this attentive learning would reinforce this desired proximity and adjust the classifier weights conditioned on the query. Consequently, the intra-class variation can be mitigated.
实验结果
-
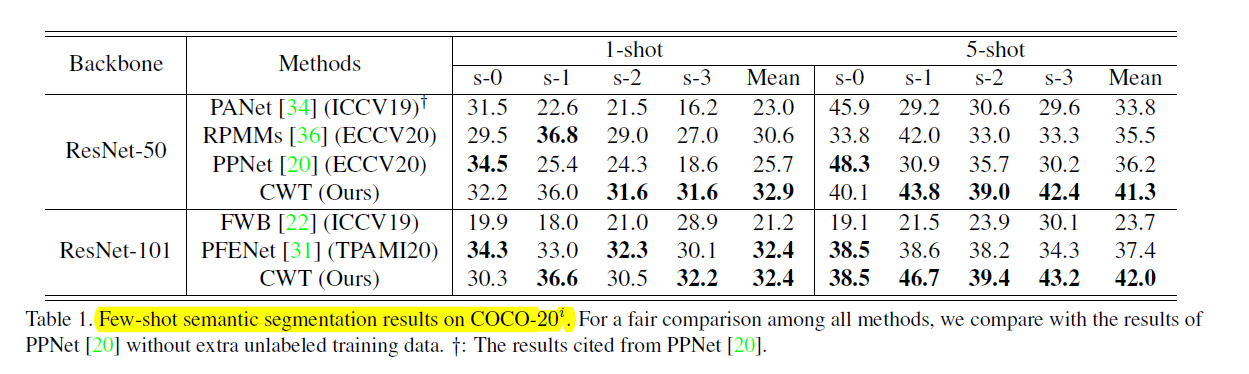
COCO-20上的实验结果对比:
-
PASCAL-5上的实验结果对比:
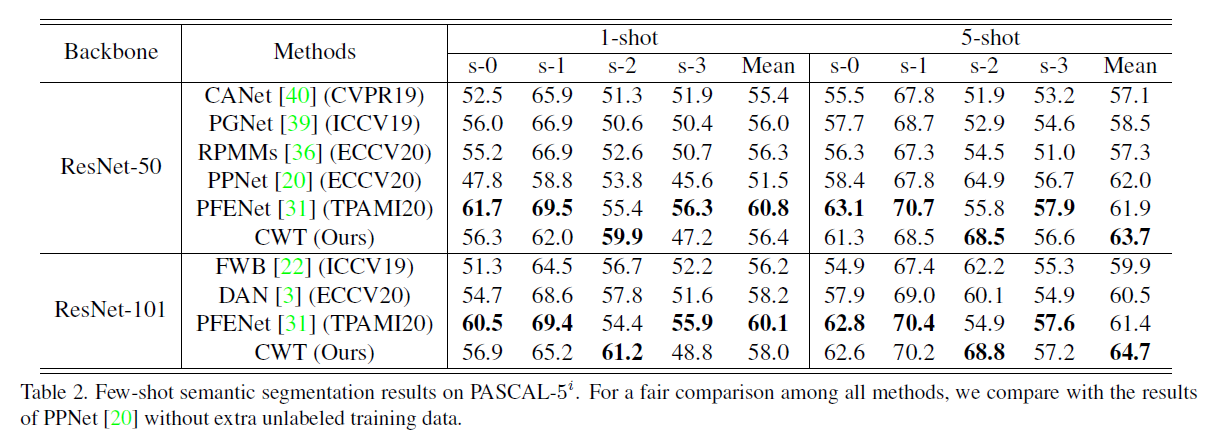
作者认为在PASCAL-5数据集上的性能并不是很好,其中的一个原因可能是PASCAL的训练集的类别和图像太少,无法满足本文的要求或者假设:预训练的特征提取器必须是类不可知的??
消融实验
- 对整个模型使用元学习策略 vs 仅仅对分类器的学习使用元学习策略
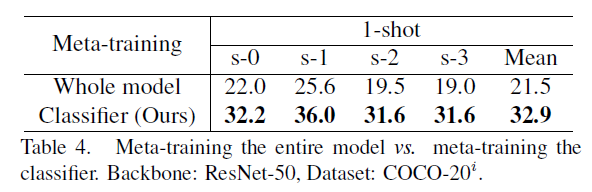
哈哈作者在整个模型上使用元学习策略训练,结果比较惨,猜测对整个模型进行训练结果较差的一个原因是:作者提出的自适应分类器参数还是较多的(参考DVBE_ZSL的那个的分类器),使得模型学到一个知识迁移能力强的分类器头比较困难,容易在特征提取器上过拟合整个训练集。
- 是否使用自适应分类器
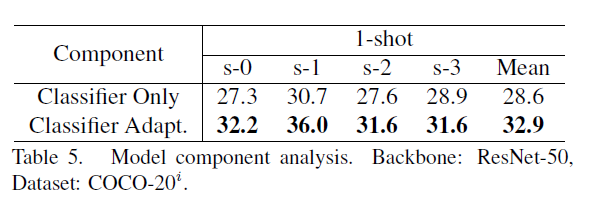
这自适应分类器貌似作者做的比较work,给模型带来了不少的提升。 ###