DA Classification
Transferable Semantic Augmentation for Domain Adaptation
- 会议: CVPR 2021
- 作者:北京理工大学
-
代码:github
-
Motivation and Contribution
- 作者认为深度学习网络一定程度上可以使得特征线性化(原文中 deep networks excel at disentangling the underlying factors of data variation and linearizing the deep features ),某些方向维度上的改变往往和一些语义上的转换相关,比如背景变换,亮度变换等。那么源域的特征也可以通过合适的变换得到朝着目标域语义的特征。 (作者引用了文章[41, 45]佐证自己的观点)。 但是这些变换中仅有一部分对于特定的任务是有意义的。
- 本文的主要思想就是来自于 ISDA[45],这篇文章首次提出了使用类方差来增强图像特征, 作为一种有效的正则化深度网络的数据增强技术,该方法可以有效改善模型的泛化性能。本文则是在ISDA的基础上做出了进一步的扩展
- 本文将这种增强技术应用在无监督域适应分类任务上,此外作者在ISDA的基础上做出了两点有效的改进,第一是将原先的均值为0的高斯分布采样增强技术,修正为在类别的均值的高斯分布采样来增强数据应用在域适应分类任务上,第二就是将原先的方差的迭代计算修改为使用
memory module, 实验表明这两点在域适应分类任务上取得了明显的提升。 - 仿照ISDA的做法,本文也从理论上将该方法进行了优化,不是显式地从高斯分布中采样得到增强数据计算交叉熵损失,而是计算得到一个增强后数据的交叉熵损失的上界,然后运用新的交叉熵损失函数去优化模型。
- 作者提出TSA技术作为一个即插即用的插件在多个方法上都可以明显地提升原始模型的效果。
- 本文将这种增强技术应用在无监督域适应分类任务上,此外作者在ISDA的基础上做出了两点有效的改进,第一是将原先的均值为0的高斯分布采样增强技术,修正为在类别的均值的高斯分布采样来增强数据应用在域适应分类任务上,第二就是将原先的方差的迭代计算修改为使用
-
关于高斯分布的均值和方差的值的计算
- 均值是源域中的类均值和目标域中类均值的差 $\Delta \mu = \mu_{s} - \mu_{t}$。
-
方差是目标域中类的方差。
- 文章关于二者的叙述如下:

-
关于损失函数Transferable CrossEntropy Loss的推导

作者认为为了取得好的性能,M 作为数据增强的次数通常是越大越好,但是这样会带来计算上的开销。于是作者按照ISDA[45]的推导思路得到了在M无穷大的情况下的交叉熵损失函数即Transferable CrossEntropy Loss。 最终只用优化该损失函数就可以。

-
实验分析
-
作者将TSA插件应用到之前的方法中,均获得了明显的提升。
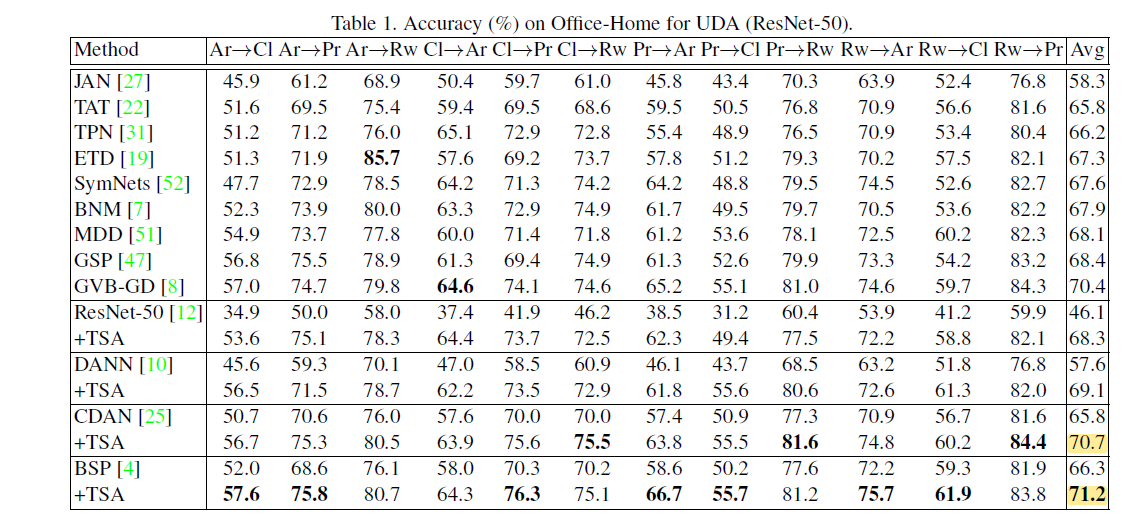
-
消融实验
下图是验证基于类均值的高斯分布采样更有利用域适应学习,但是没有mutual information minimizing loss, TSA好像也就比ISDA强一点。

此外作者还验证了自己将ISDA的迭代更新方差修改为只计算当前batch的方差对模型的性能提升。
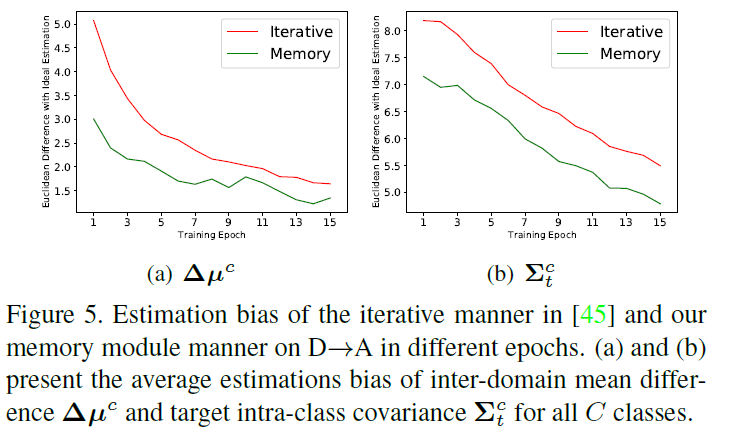
-
超参数分析,作者用热度图的形式更加简洁明了展示了超参数对模型的影响,值得借鉴!
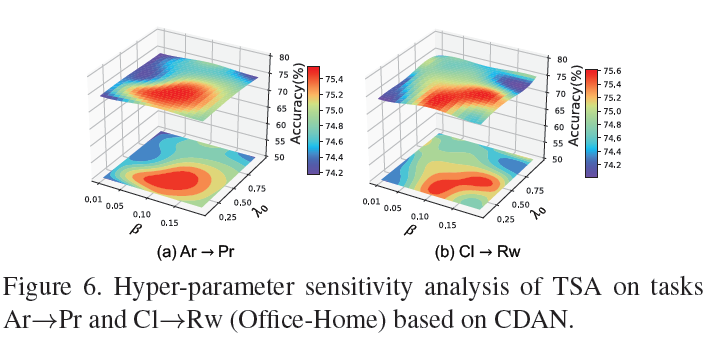
-
[41] Deep feature interpolation for image content changes, CVPR2017 </br> [45] Implicit semantic data augmentation for deep networks, NeurIP 2019
Bidirectional Learning for Domain Adaptation of Semantic Segmentation
- 会议: CVPR2019
- 作者:加州大学圣地亚哥分校
-
代码: github
-
Motivation
-
Contribution
-
模型示意图
- 实验结果
Learning to Adapt Structured Output Space for Semantic Segmentation
- 会议:CVPR2018
- 作者:NEC Laboratories America
-
代码: github
-
Motivation 对于域适应语义分割任务而言,虽然源域和目标域的图像的外观风格可能存在差异,但是他们语义分割的结果应该都存在一定相似的结构特征,比如说空间布局和局部的上下文关系。
- Contribution
- 提出了一种针对像素级语义分割任务的对抗学习方法
- 提出并论证了输出即分割空间的适应学习可以有效对齐源域和目标域之间的场景布局和局部上下文关系。
- 此外作者设计了在多个层级上使用对抗学习来适应学习源域和目标域的特征,多层特征的对抗学习可以进一步改善模型的性能。
- 模型示意图
模型的学习过程为:
-
首先使用带标签源域图像去监督训练分割模型,然后使用训练好的分割模型去预测目标域的图像得到初步的目标域分割结果.
\[\mathcal{L}_{\text {seg }}\left(I_{s}\right)=-\sum_{h, w} \sum_{c \in C} Y_{s}^{(h, w, c)} \log \left(P_{s}^{(h, w, c)}\right)\] -
训练学习对抗学习使用到的分类器
\[\begin{array}{r} \mathcal{L}_{d}(P)=-\sum_{h, w}(1-z) \log \left(\mathbf{D}(P)^{(h, w, 0)}\right) +z \log \left(\mathbf{D}(P)^{(h, w, 1)}\right) \end{array}\]Discriminator, 损失函数为:$z=0$表示像素标签是目标域,$z=1$则表示像素标签是源域。{.success}
-
目标域图像得到的分割结果$P_{t}$一起输入到判别器网络进行判别,期望$P_{s}$和$P_{t}$的分布趋向一致,从而消除目标域分割结果存在的噪声问题。 对抗损失函数为:
\[\mathcal{L}_{adv}(I_{t})=-\sum_{h, w} \log \left(\mathbf{D}(P_{t})^{(h, w, 1)} \right)\]
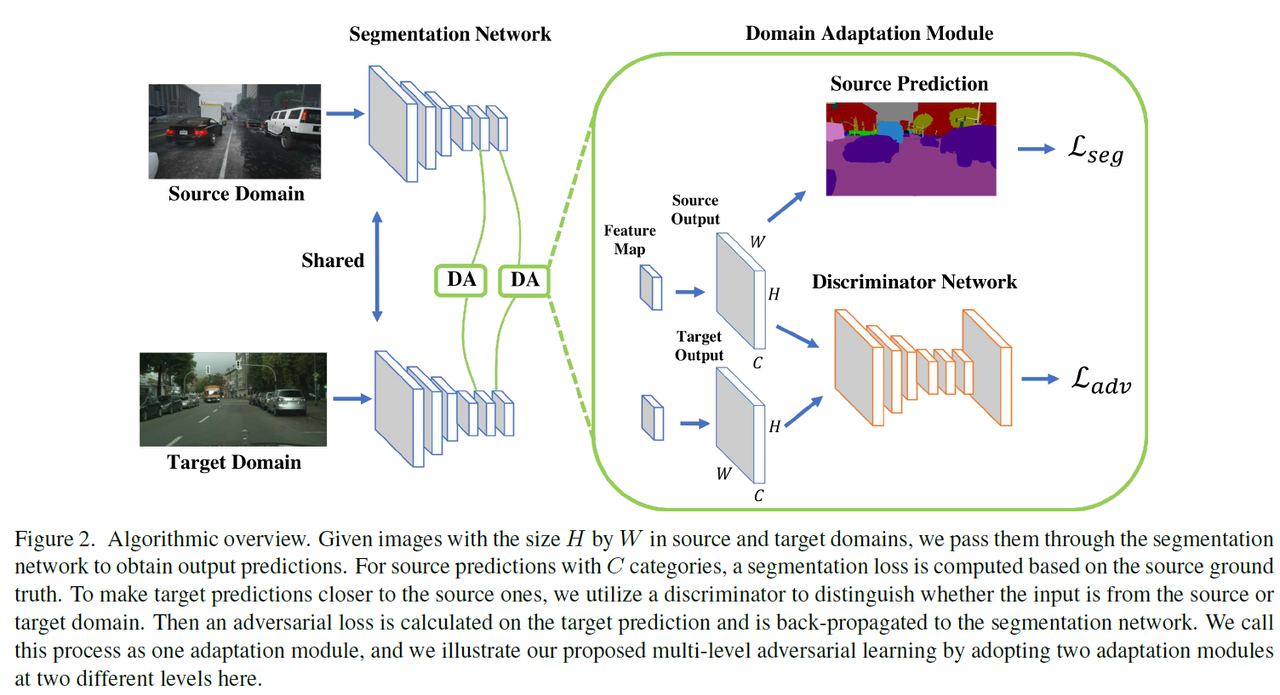
-
-
实验结果
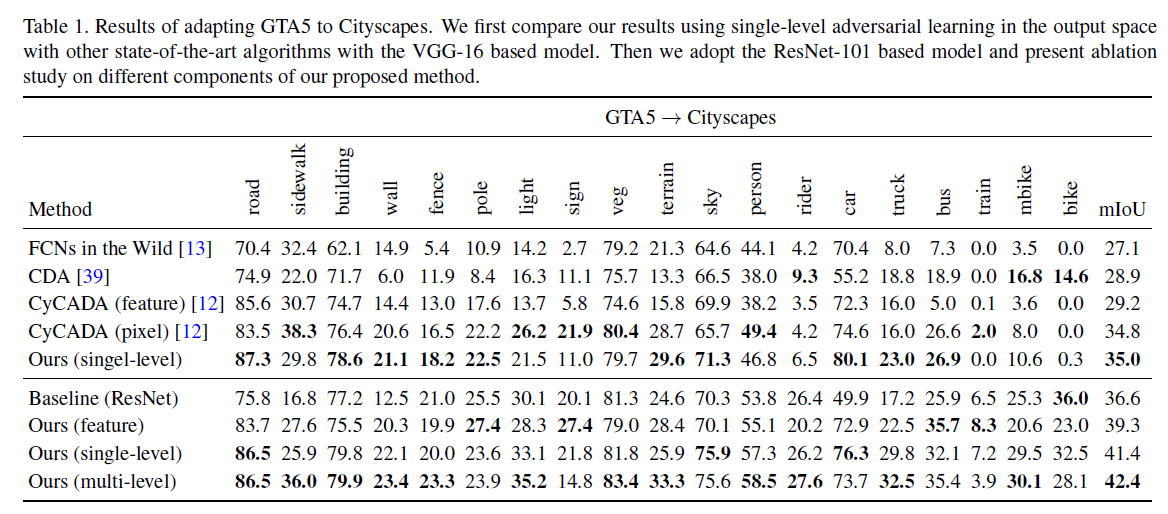
上方的对比模型都使用了VGG网络作为骨干网络,下面则使用ResNet-101,可以看出ResNet-101有很大优势。
作者在文中的可视化实验当中也证实了本文的对抗学习方法可以去除目标域分割结果的噪声,但是在边缘上的分割结果仍然存在不足。

DA Re-ID
IDM: An Intermediate Domain Module for Domain Adaptive Person Re-ID
- ICCV 2021 oral
- Author: Peking University
- github
- Motivation and Contribution
- Existing methods have made great progress in UDA re-ID, but they have not explicitly considered the bridging between the two extreme domains, i.e.,what information about the similarity/dissimilarity of the two domains can be utilized to tackle the UDA re-ID task. We explicitly and comprehensively investigate into the bridging between the source and target domains.
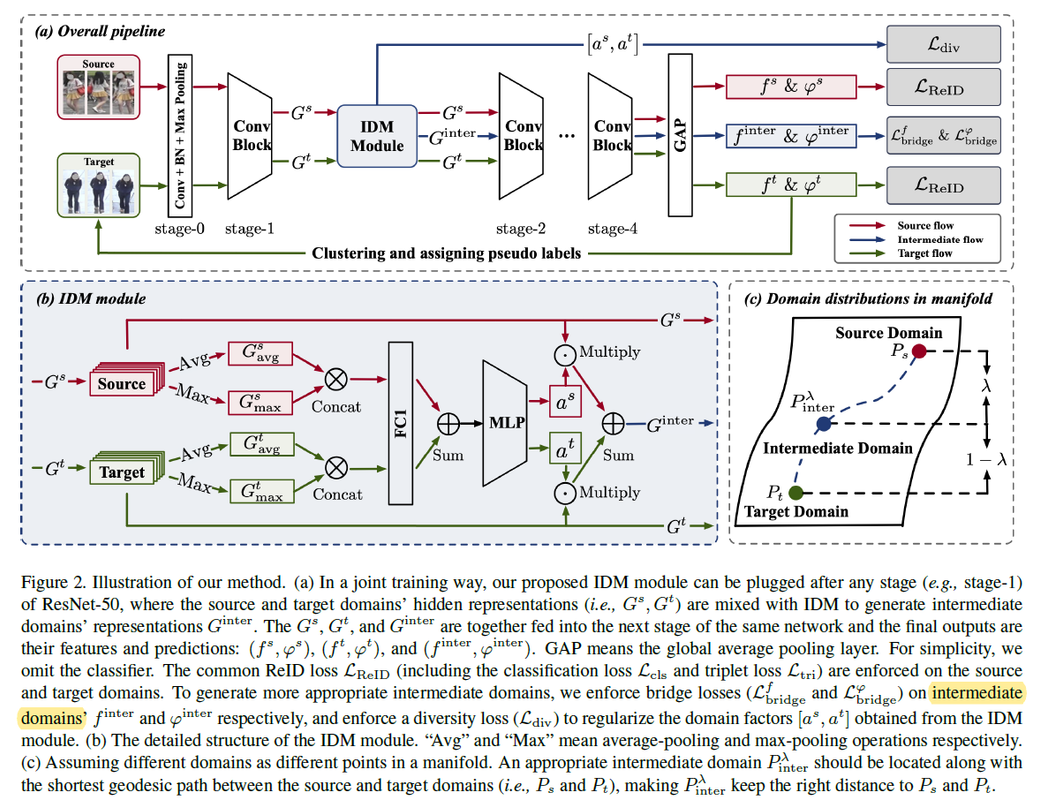
- 在DA-ReID基于MixUp的思想,设计IDM模块去有效混合源域和目标域样本,使用生成的中间域样本去辅助原先任务的训练.
- 值得复现实验结果
Multiple Expert Brainstorming for Domain Adaptive Person Re-identification
- 会议: ECCV2020
- 作者:北大数字媒体研究所/Yonghong Tian组
- 代码: github
- Motivation and Contribution
- 为域适应Re-ID任务提出了一种可行的模型集成学习解决方案
multiple expert brainstorming network (MEB-Net), 该模型首先使用了三种不同的深度骨干网络在带标签源域数据上训练,然后在第二阶段中,采用互学习策略学习三个模型在目标域数据的适应。 在第二阶段的互学习中,作者提出了两种互学习损失Mutual identity loss和Mutual triplet loss,每个模型都通过这两个互学习损失进行优化。 - 为了调和不同专家模型的特征分类性能,作者还设计了一种
Authority Regularization来加权每个模型优化时用到的互学习损失。 - 在当时取得了SOTA,性能提升显著,主要使用了
Market-1501 and DukeMTMC-reID两个数据集。
- 为域适应Re-ID任务提出了一种可行的模型集成学习解决方案
-
模型示意图
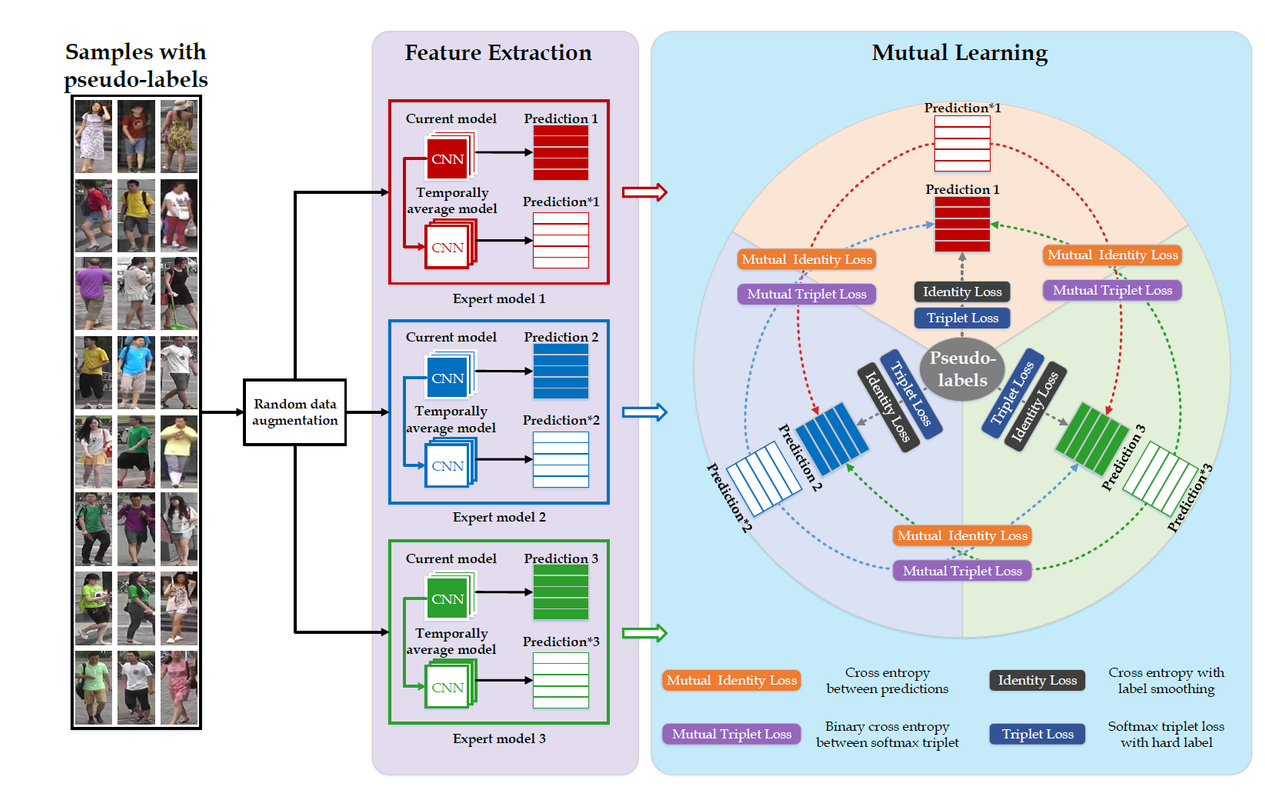
关于源域上的学习使用到了两个损失,行人ID预测的
\[\mathcal{L}_{s, t r i}^{k}=-\frac{1}{N_{s}} \sum_{i=1}^{N_{s}} \log \frac{e^{\left\|f\left(x_{s, i} \mid \theta^{k}\right)-f\left(x_{s, i-} \mid \theta^{k}\right)\right\|}}{e^{\left\|f\left(x_{s, i} \mid \theta^{k}\right)-f\left(x_{s, i+} \mid \theta^{k}\right)\right\|}+e^{\left\|f\left(x_{s, i} \mid \theta^{k}\right)-f\left(x_{s, i-} \mid \theta^{k}\right)\right\|}}\]交叉熵损失(使用了label smoothing技术)$L_{s, id}$和正负样本triple loss$L_{s, tri}$, $s$表示源域。 \(\mathcal{L}_{s, i d}^{k}=\frac{1}{N_{s}} \sum_{i=1}^{N_{s}} \sum_{j=1}^{M_{s}} q_{j} \log p_{j}\left(x_{s, i} \mid \theta^{k}\right)\)这两个损失和在目标域适应阶段使用的损失基本一致,只是标签换成了其它专家模型预测的标签即
Soft Class Labels. 作者在文中说直接使用专家模型比如$\mathcal{M}^{k}$的预测结果作为其它专家模型的标签,有可能传播放大预测的不准确性。 因此作者使用指数移动平均技术EMA(半监督学习一致性正则化)去得到专家模型更加可靠的预测结果(为什么会更加可靠还不太清楚?),有了其他专家模型的预测结果,那么将其作为标签代入上面两个损失计算公式作为模型$\mathcal{M}^{k}$的互学习损失。Authority Regularization就是根据不同模型对目标域数据的分类能力(依据ICC,类之间的距离方差和类内的方差比值)去平衡各个专家模型的损失,因为对于每个其他的专家模型的预测结果,$\mathcal{M}^{k}$都要计算一对互学习损失,那么该正则化就是对不同专家模型的损失乘上一个权重。 - 实验结果
-
Market-1501 and DukeMTMC-reID两个数据集上的结果提升明显
-
消融实验
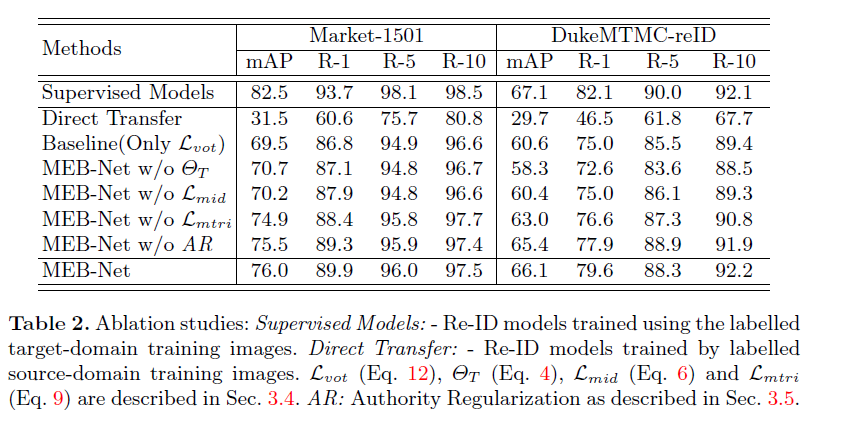
第一行
Supervised Models作者给出了在有监督下的任务的上限,此外AR正则化对模型的提升不是很大,指数移动平均还有ID交叉熵损失对模型的比较大。
-
Group-aware Label Transfer for Domain Adaptive Person Re-identification
- CVPR 2021
- Author: Kecheng Zheng University of Science and Technology of China
- github
- 该仓库包括了好几个模型的代码复现
-
- Motivation and Contribution
DA Object Detection
Domain Adaptation for Object Detection / 域适应目标检测数据集
KITTI
- 下载地址
- 需要注册,进去主页后选择下载
Download left color images of object data set (12 GB).
- 需要注册,进去主页后选择下载
- KITTI是一个自动驾驶的数据集,刚才下载的数据集里有7481张训练集图片和7518张测试集图片, 只能使用训练集训练模型,但是不能用来测试模型。因此只能下载到训练集的标签。
CityScapes
- CityScapes是一个是一个语义分割数据集,一共5000张图片,包括2975张训练图片、500张验证图片5和1525张测试图,每张图片大小都是1024x2048。每张图片都有像素级的标注,经过转换后,可以用于目标检测任务。该数据集都是正常天气下不同城市的市区场景,目标物体主要是行人、车辆等。
Foggy Cityscapes
下载地址 Foggy Cityscapes是在Cityscapes数据集基础上添加人工合成的雾制作而成,因而标注信息和原Cityscapes数据集完全相同。
BDD 100K
Exploring Categorical Regularization for Domain Adaptive Object Detection
DA Semantic Segmentation
Cross-View Regularization for Domain Adaptive Panoptic Segmentation
- 会议: CVPR 2021
- 作者:南洋理工大学
-
代码:未开源
- Motivation and Contribution

- 作者首次提出并解决全景分割任务上的域适应问题。全景分割是语义分割和实例分割的综合体,作者观察到语义分割模型和实例分割模型有不同特质,语义分割模型往往在不定形区域上分割较好,而在行人或者自行车这些物体上分割不好。
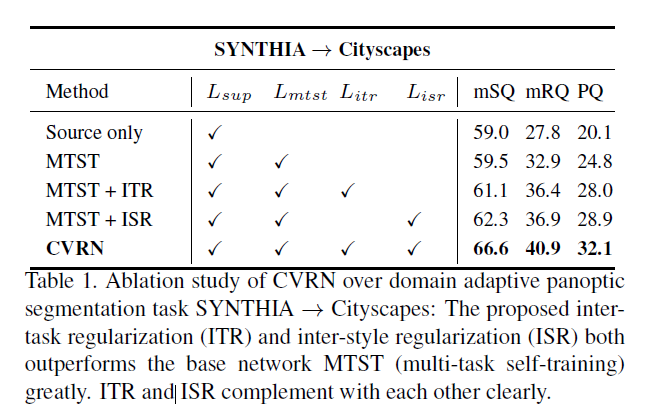
This design is inspired by our observations that semantic segmentation usually performs clearly better for amorphous regions called "stuff" as compared with countable objects called "things" whereas instance segmentation usually performs in an opposite manner。因此作者提出使用两个任务互相正则化的方法(InterTask Regularization),改善模型在目标域上的全景分割预测结果,再按照伪标签技术筛选出经过正则化的模型校正后的结果作为标签,去进一步训练模型。 -
此外作者还通过不同风格的增强技术,来促使同一张图像在不同域上的预测一致性。(
inter-style regularizer). - 消融实验
MTST是作者使用的baseline模型,该模型将全景分割任务转换为实例分割和语义分割两个子任务的学习。
- 不同数据集上的实验
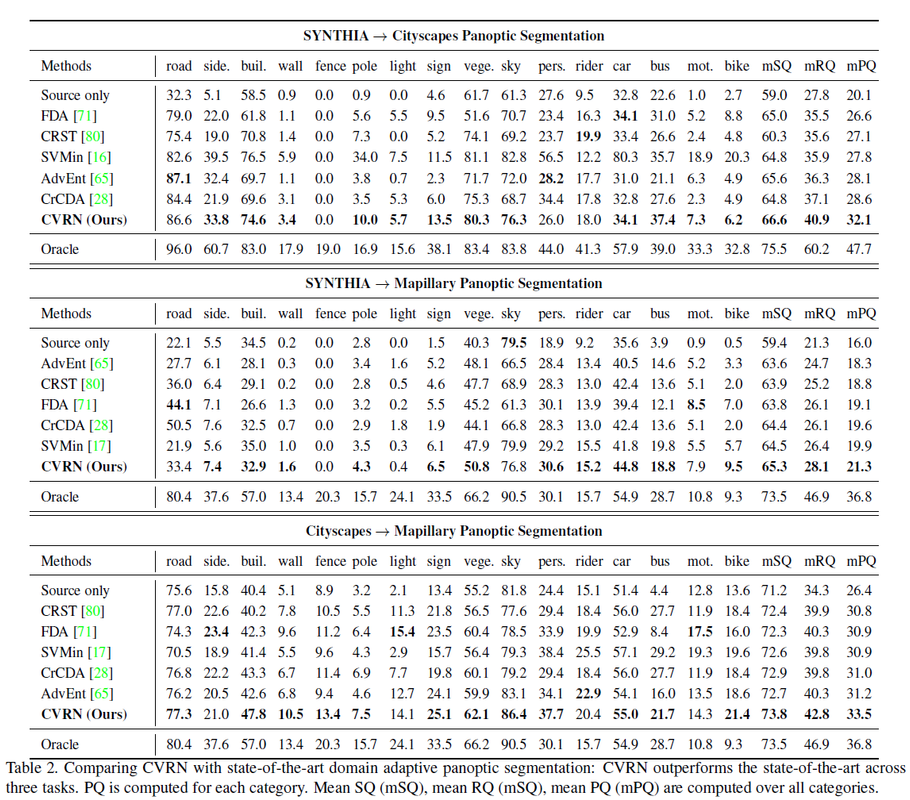
更多分析参考原文
很多work的idea都是出自于平时实验的积累,CVPR上的另一篇文章和本文idea也比较相似
与其任务相关的一篇文章CVPR2021 Fully Convolutional Networks for Panoptic Segmentation Panoptic FCN:真正End-to-End的全景分割