SOTA List
-
GTA5-2-Cityscapes
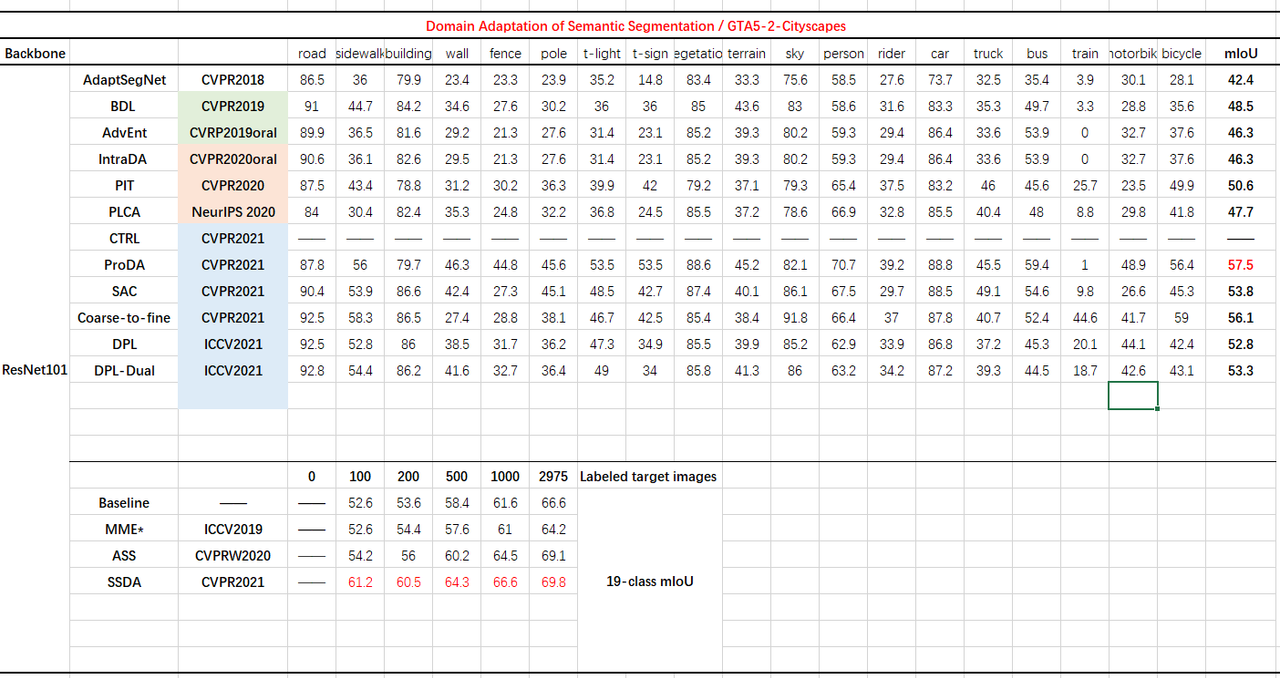
-
SYNTHIA-2-Cityscapes
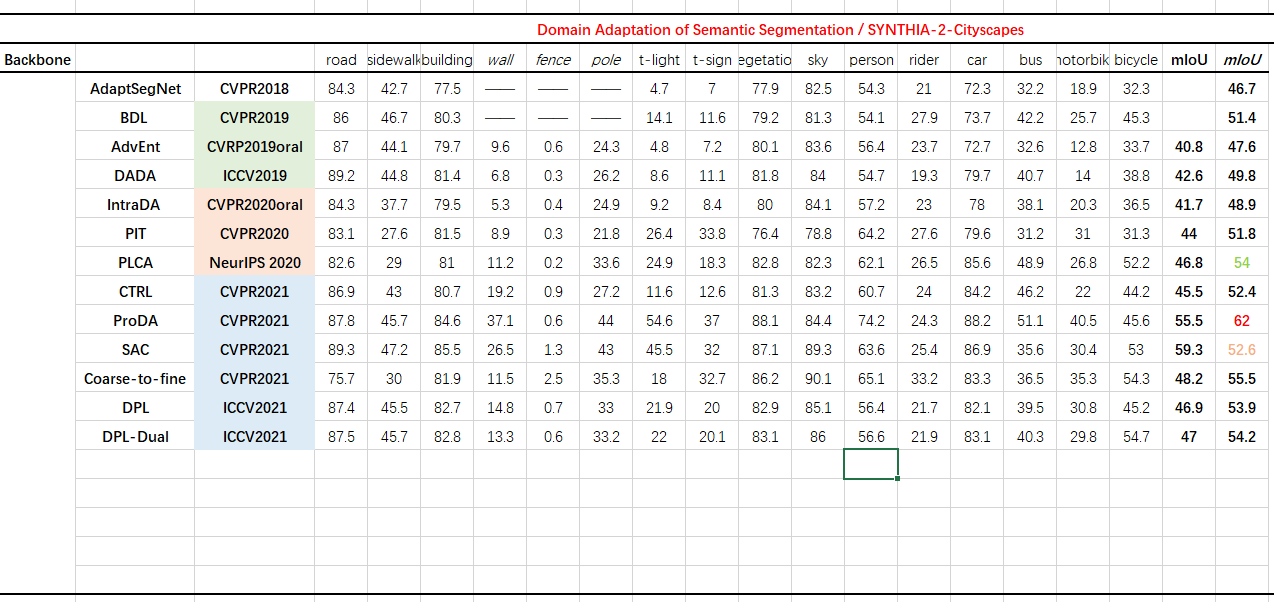
-
上表中列出的关于无监督域适应语义分割的文章链接和代码库链接
AdaptSegNet Learning to Adapt Structured Output Space for Semantic Segmentation
github
BDL Bidirectional Learning for Domain Adaptation of Semantic Segmentation
github
AdvEnt Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation
github
IntraDA Intra-domain Adaptation for Semantic Segmentation through Self-Supervision
github
PIT Cross-domain semantic segmentation via domain-invariant interactive relation transfer
github
PLCA Pixel-Level Cycle Association: A New Perspective for Domain Adaptive Semantic Segmentation
github
CTRL Learning to Relate Depth and Semantics for Unsupervised Domain Adaptation
github
ProDA Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation
github
SAC Self-supervised Augmentation Consistency for Adapting Semantic Segmentation
github
Coarse-to-fine Coarse-to-Fine Domain Adaptive Semantic Segmentation with Photometric Alignment and Category-Center Regularization
github -
上表中列出的半监督域适应语义分割的文章链接和代码库链接
MME Semi-supervised domain adaptation via minimax entropy
githubASS Alleviating semantic-level shift: A semi-supervised domain adaptation method for semantic segmentation
githubSSDA Semi-supervised Domain Adaptation based on Dual-level Domain Mixing for Semantic Segmentation
github
Bidirectional Learning for Domain Adaptation of Semantic Segmentation
- 会议: CVPR2019
- 作者:加州大学圣地亚哥分校
-
代码: github
-
Motivation
-
Contribution
-
模型示意图
- 实验结果
Learning to Adapt Structured Output Space for Semantic Segmentation
- 会议:CVPR2018
- 作者:NEC Laboratories America
-
代码: github
-
Motivation 对于域适应语义分割任务而言,虽然源域和目标域的图像的外观风格可能存在差异,但是他们语义分割的结果应该都存在一定相似的结构特征,比如说空间布局和局部的上下文关系。
- Contribution
- 提出了一种针对像素级语义分割任务的对抗学习方法
- 提出并论证了输出即分割空间的适应学习可以有效对齐源域和目标域之间的场景布局和局部上下文关系。
- 此外作者设计了在多个层级上使用对抗学习来适应学习源域和目标域的特征,多层特征的对抗学习可以进一步改善模型的性能。
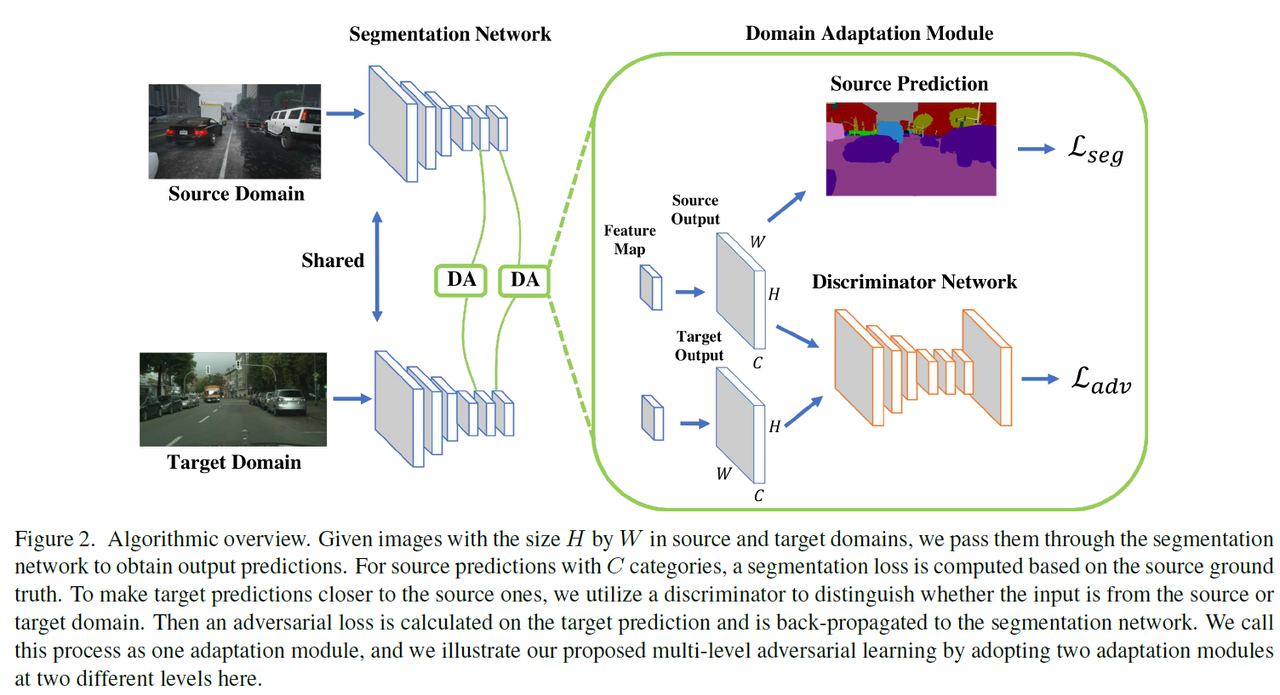
- 模型示意图
模型的学习过程为:
-
首先使用带标签源域图像去监督训练分割模型,然后使用训练好的分割模型去预测目标域的图像得到初步的目标域分割结果.
\[\mathcal{L}_{\text {seg }}\left(I_{s}\right)=-\sum_{h, w} \sum_{c \in C} Y_{s}^{(h, w, c)} \log \left(P_{s}^{(h, w, c)}\right)\] -
训练学习对抗学习使用到的分类器
\[\begin{array}{r} \mathcal{L}_{d}(P)=-\sum_{h, w}(1-z) \log \left(\mathbf{D}(P)^{(h, w, 0)}\right) +z \log \left(\mathbf{D}(P)^{(h, w, 1)}\right) \end{array}\]Discriminator, 损失函数为:$z=0$表示像素标签是目标域,$z=1$则表示像素标签是源域。{.success}
-
目标域图像得到的分割结果$P_{t}$一起输入到判别器网络进行判别,期望$P_{s}$和$P_{t}$的分布趋向一致,从而消除目标域分割结果存在的噪声问题。 对抗损失函数为:
\[\mathcal{L}_{adv}(I_{t})=-\sum_{h, w} \log \left(\mathbf{D}(P_{t})^{(h, w, 1)} \right)\]
-
-
实验结果
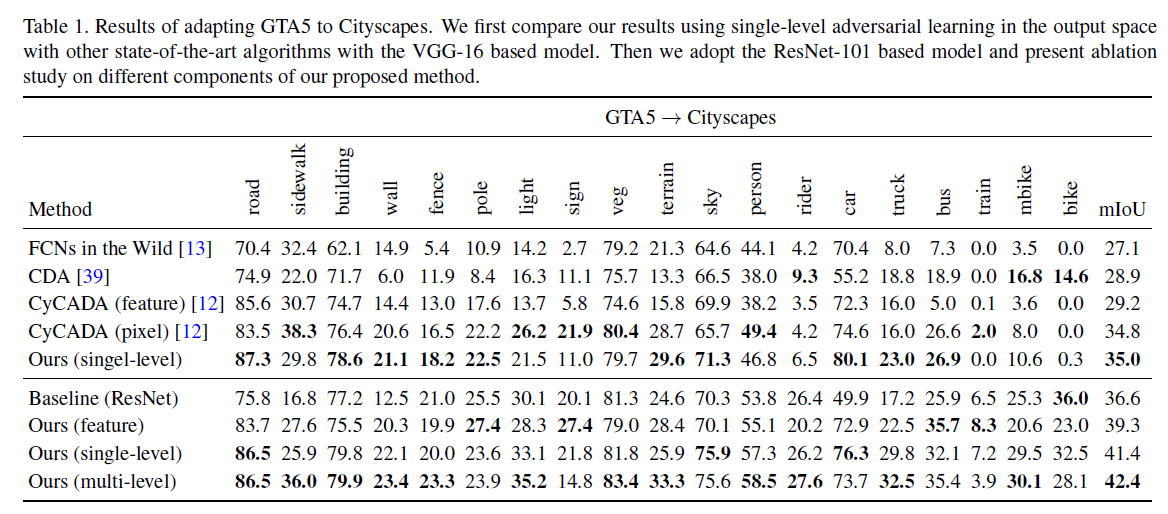
上方的对比模型都使用了VGG网络作为骨干网络,下面则使用ResNet-101,可以看出ResNet-101有很大优势。
作者在文中的可视化实验当中也证实了本文的对抗学习方法可以去除目标域分割结果的噪声,但是在边缘上的分割结果仍然存在不足。

Cross-View Regularization for Domain Adaptive Panoptic Segmentation
- 会议: CVPR 2021
- 作者:南洋理工大学
-
代码:未开源
- Motivation and Contribution

- 作者首次提出并解决全景分割任务上的域适应问题。全景分割是语义分割和实例分割的综合体,作者观察到语义分割模型和实例分割模型有不同特质,语义分割模型往往在不定形区域上分割较好,而在行人或者自行车这些物体上分割不好。
This design is inspired by our observations that semantic segmentation usually performs clearly better for amorphous regions called "stuff" as compared with countable objects called "things" whereas instance segmentation usually performs in an opposite manner。因此作者提出使用两个任务互相正则化的方法(InterTask Regularization),改善模型在目标域上的全景分割预测结果,再按照伪标签技术筛选出经过正则化的模型校正后的结果作为标签,去进一步训练模型。 -
此外作者还通过不同风格的增强技术,来促使同一张图像在不同域上的预测一致性。(
inter-style regularizer). - 消融实验
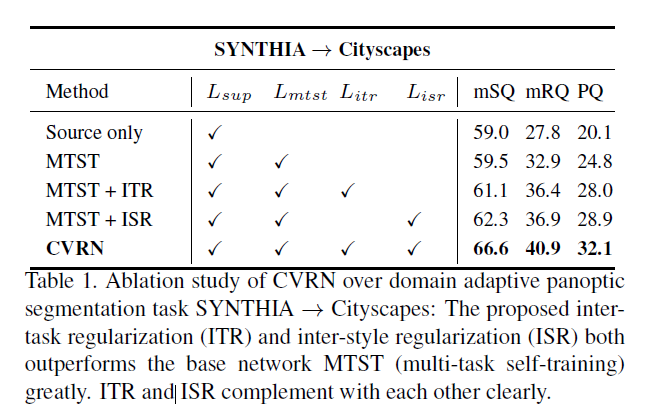
MTST是作者使用的baseline模型,该模型将全景分割任务转换为实例分割和语义分割两个子任务的学习。
- 不同数据集上的实验
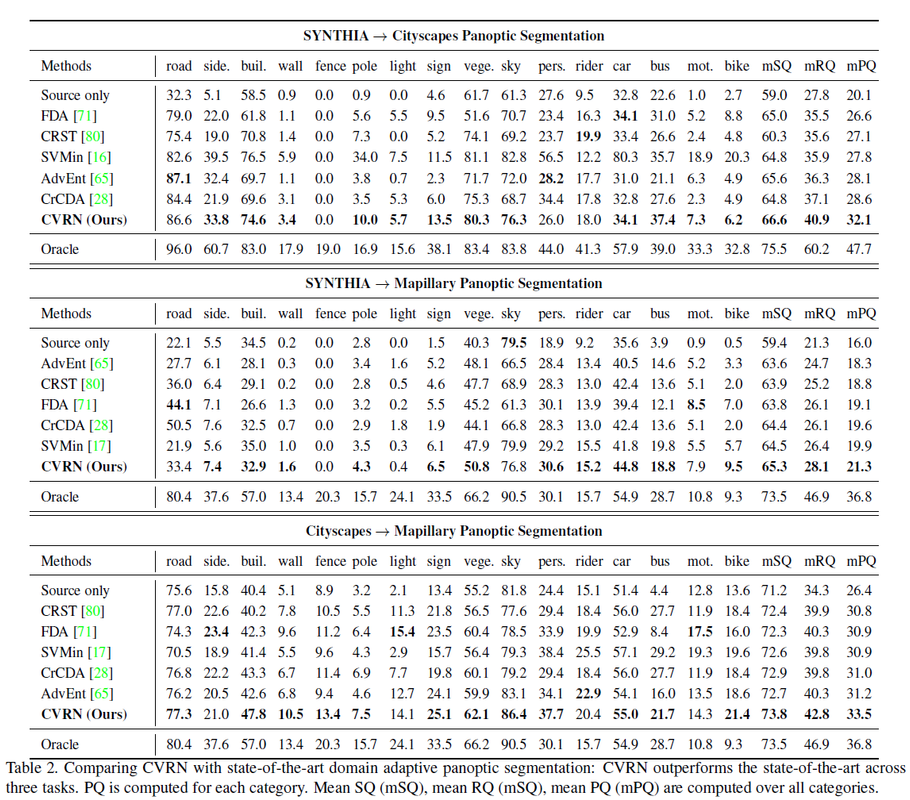
更多分析参考原文
很多work的idea都是出自于平时实验的积累,CVPR上的另一篇文章和本文idea也比较相似
与其任务相关的一篇文章CVPR2021 Fully Convolutional Networks for Panoptic Segmentation Panoptic FCN:真正End-to-End的全景分割