1. C2F_ZSL_CVPR
思路整理:
1.1 验证GMIX的 Motivation 实验
验证方案一
- Woodpecker超类
- seen : ‘189.Red_bellied_Woodpecker’、’192.Downy_Woodpecker’、’187.American_Three_toed_Woodpecker’
- unseen : ‘188.Pileated_Woodpecker’、’190.Red_cockaded_Woodpecker’、’191.Red_headed_Woodpecker’
- Warbler超类
- seen 17个子类: ‘158.Bay_breasted_Warbler’、’159.Black_and_white_Warbler’、’160.Black_throated_Blue_Warbler’、’162.Canada_Warbler’、’167.Hooded_Warbler’、 ‘170.Mourning_Warbler’、’171.Myrtle_Warbler’、’172.Nashville_Warbler’、’174.Palm_Warbler’、’175.Pine_Warbler’、’176.Prairie_Warbler’、 ‘177.Prothonotary_Warbler’、’178.Swainson_Warbler’、’179.Tennessee_Warbler’、’181.Worm_eating_Warbler’、’182.Yellow_Warbler’、 ‘166.Golden_winged_Warbler’
- unseen 5个子类: ‘161.Blue_winged_Warbler’、’164.Cerulean_Warbler’、’168.Kentucky_Warbler’、’169.Magnolia_Warbler’、’173.Orange_crowned_Warbler’
- Sparrow超类 :
- seen 14个子类: ‘115.Brewer_Sparrow’、’116.Chipping_Sparrow’、’117.Clay_colored_Sparrow’、’118.House_Sparrow’、’120.Fox_Sparrow’、 ‘122.Harris_Sparrow’、’125.Lincoln_Sparrow’、’126.Nelson_Sharp_tailed_Sparrow’、’128.Seaside_Sparrow’、’129.Song_Sparrow’、 ‘131.Vesper_Sparrow’、’133.White_throated_Sparrow’、’114.Black_throated_Sparrow’、’121.Grasshopper_Sparrow’
- unseen 5个子类: ‘113.Baird_Sparrow’、’123.Henslow_Sparrow’、’124.Le_Conte_Sparrow’、’127.Savannah_Sparrow’、’132.White_crowned_Sparrow’
- Vireo超类
- seen : ‘151.Black_capped_Vireo’、’152.Blue_headed_Vireo’、’153.Philadelphia_Vireo’、’154.Red_eyed_Vireo’、’155.Warbling_Vireo’、
- unseen : ‘157.Yellow_throated_Vireo’、’156.White_eyed_Vireo’
1.2 不同Fine-tune方式(V2S, S2V, Vanilla-Label)得到的特征方差可视化实验
V2S和S2V数据点近邻分布的斜度比较
V2S的特征K近邻分布斜度要大于S2V,但是其映射到S空间后的K近邻分布斜度可能会小于S2V的(有待进一步可视化验证)。
线性变换是必要的吗?
- 实验上来说是必要的,线性变换有助于提升特征嵌入的泛化能力。
为了验证趋于线性的变换是有利于特征的泛化,设置了一组实验:V2S+LeakReLU(np=x),当激活函数的斜率为1.0时,
此时完全就是一个线性变化,当斜率逐渐降低时,线性减弱。
- V2S+LeakReLU(np=1.0)
- V2S+LeakReLU(np=0.8)
- V2S+LeakReLU(np=0.4)
- V2S+LeakReLU(np=0.01)
- 针对本文使用的GMIX来说,线性变换更是有必要的,理论性的简单推导:
为什么同样是线性的变换,但是S2V比 V2S的泛化能力差?
- 首先
S2V是在一个更高维的空间中进行度量学习,S2V则是在一个低维空间中进行度量学习,那么根据之前的研究工作, 我们可以想到S2V会产生比较严重的hubness问题,导致模型的分类性能降低,为了取得更好的训练结果,随着训练的不断深入, 模型就会过拟合到输入的一些噪声性特征,导致模型的泛化能力下降。 - 直觉上我觉得是因为
S2V在度量学习的时候考虑到了每个维度或者pattern,尽管这些维度有相当部分其实是任务无关的, 这就导致了最后的特征嵌入会糅杂进较多的噪声特征,一定程度上淹没了有意义的语义特征,弱化了特征的可泛化性。 -
实验结果验证如下
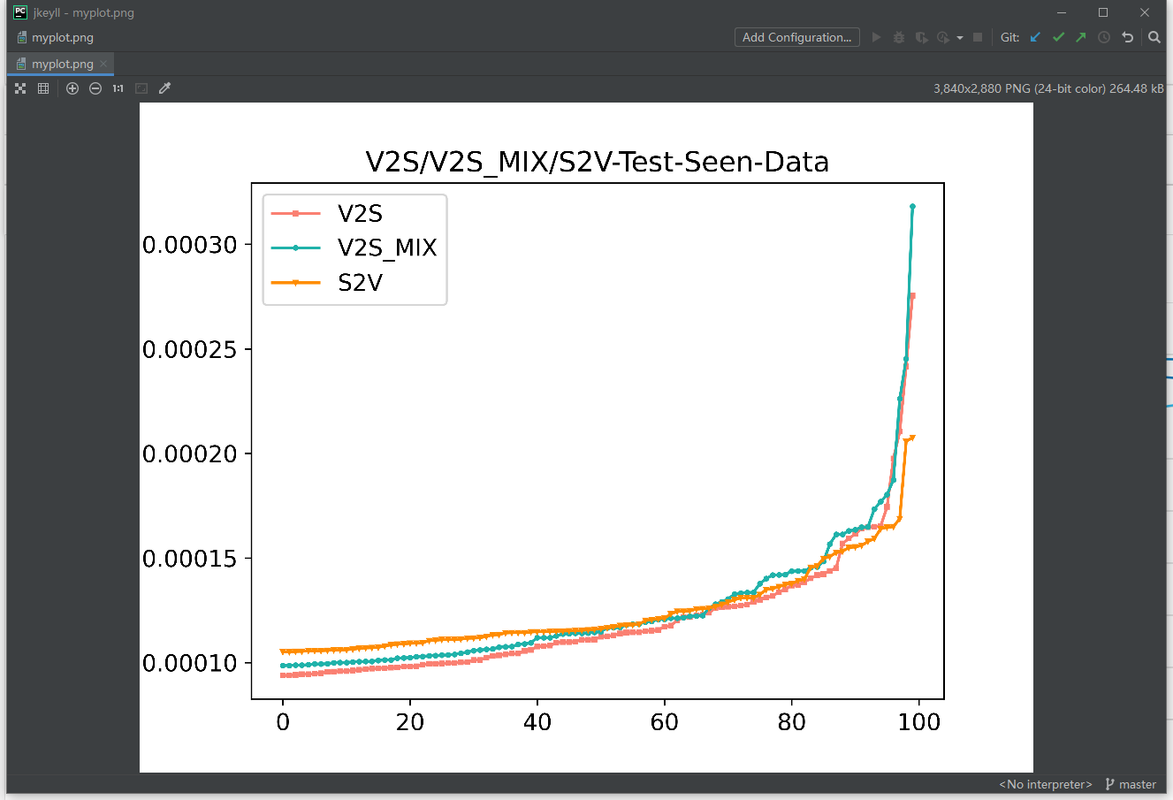
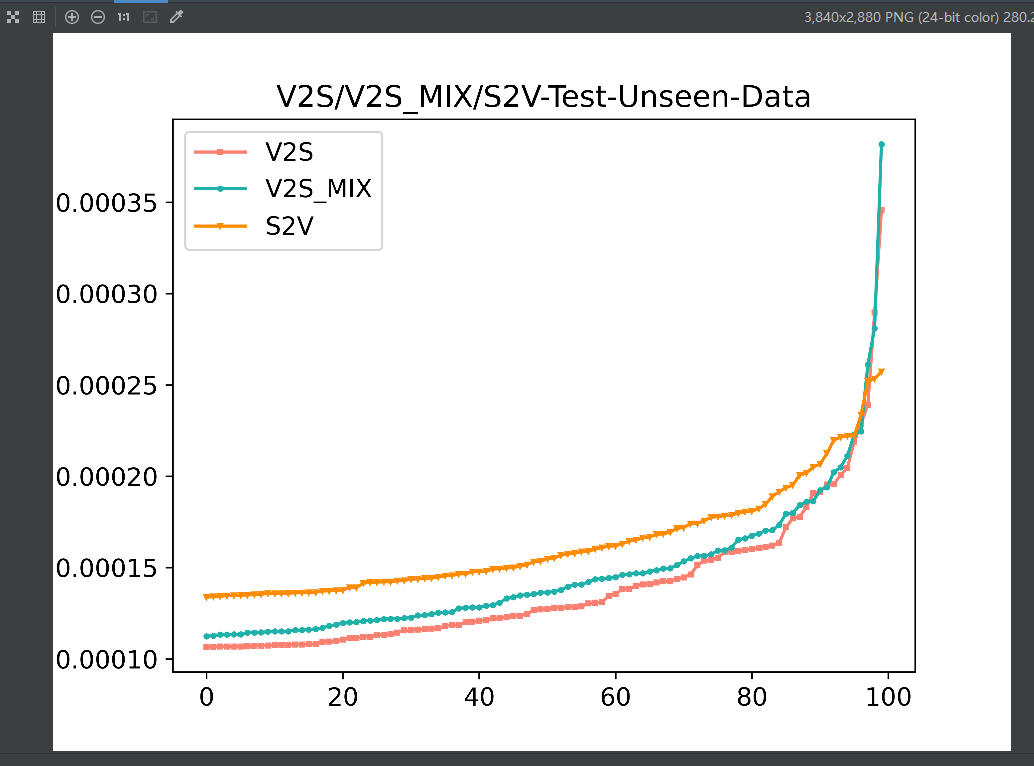
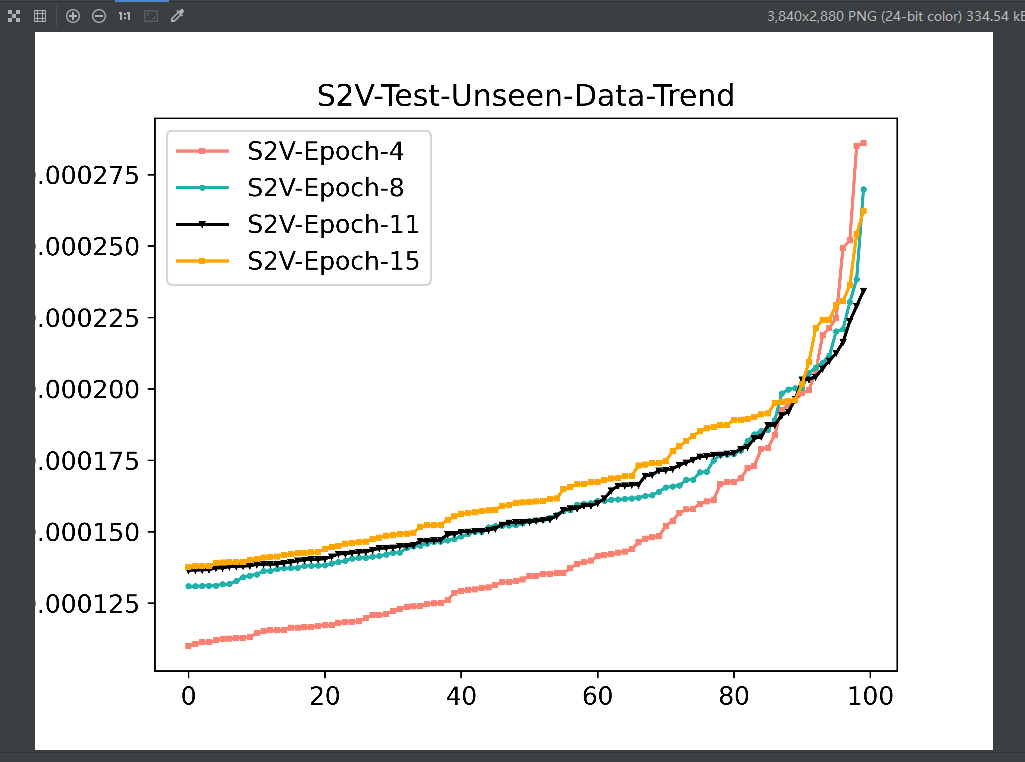
train_seen上S2V的方差是更小的, 但是在test_seen上S2V似乎更大一些, 尤其是在test_unseen上S2V的方差更为明显 再看一下随着epoch的增加,S2V在test-unseen上的方差变化, 发现其方差在开始的epoch会逐步减小,但是随着训练的进行方差反而增加,V2S在test-unseen上的方差变化则一直都是逐渐降低的.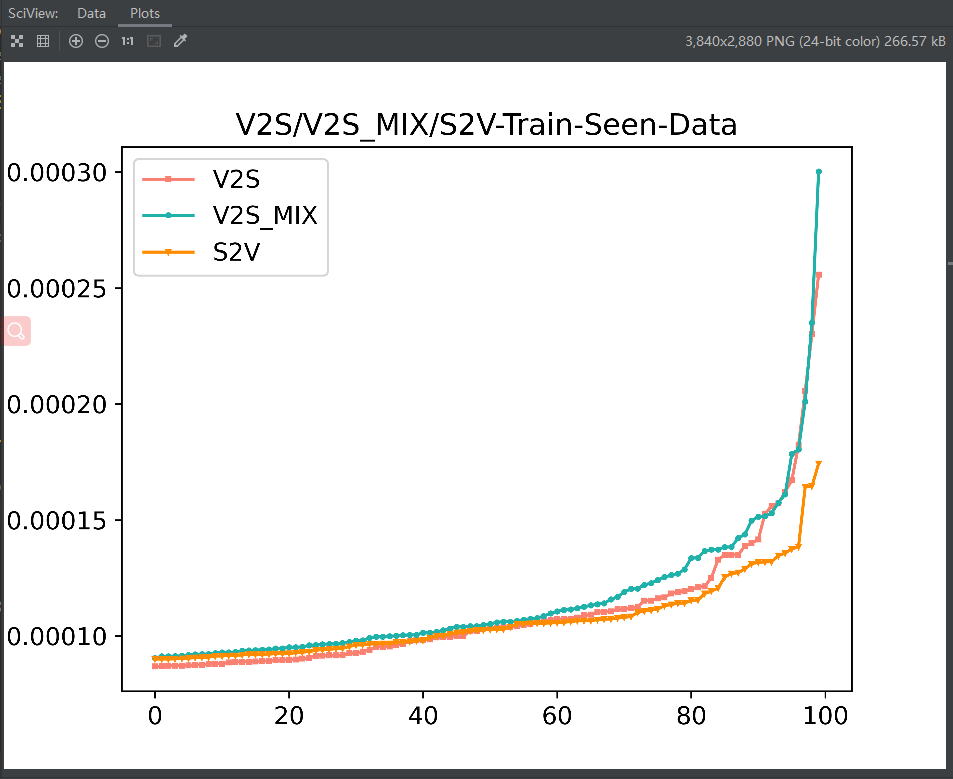
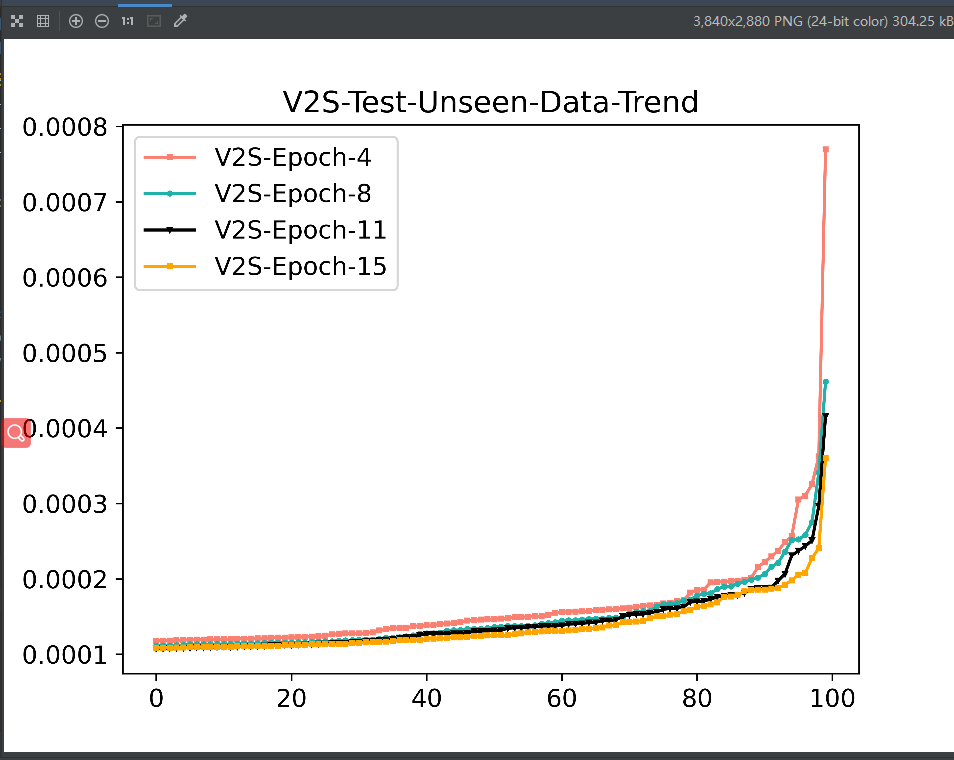
V2S一定是越是趋于线性变换越有利于特征的泛化吗 为了验证趋于线性的变换是有利于特征的泛化,设置了一组实验:V2S+LeakReLU(np=x),当激活函数的斜率为1.0时, 此时完全就是一个线性变化,当斜率逐渐降低时,线性减弱。
- V2S+LeakReLU(np=1.0)
- V2S+LeakReLU(np=0.8)
- V2S+LeakReLU(np=0.4)
- V2S+LeakReLU(np=0.01)
待做实验一
-
实验内容
-
实验目的
-
实验命令