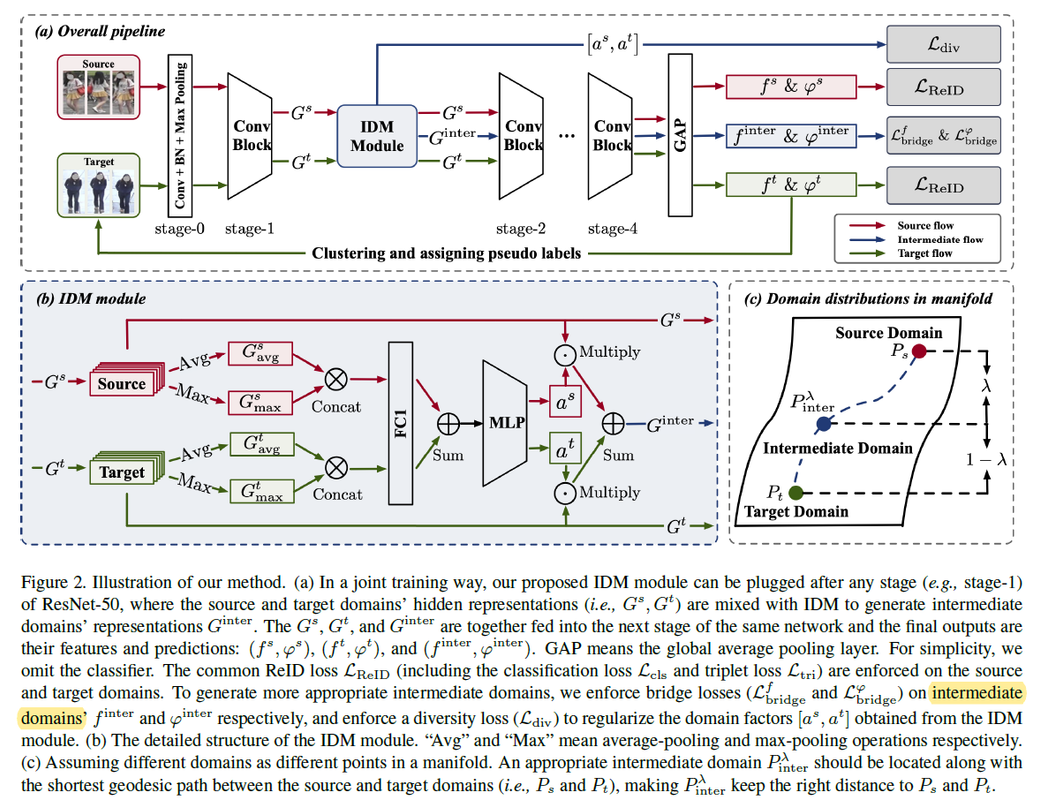
IDM: An Intermediate Domain Module for Domain Adaptive Person Re-ID
- ICCV 2021 oral
- Author: Peking University
- github
- Motivation and Contribution
- Existing methods have made great progress in UDA re-ID, but they have not explicitly considered the bridging between the two extreme domains, i.e.,what information about the similarity/dissimilarity of the two domains can be utilized to tackle the UDA re-ID task. We explicitly and comprehensively investigate into the bridging between the source and target domains.
- 在DA-ReID基于MixUp的思想,设计IDM模块去有效混合源域和目标域样本,使用生成的中间域样本去辅助原先任务的训练.
- 值得复现实验结果
Multiple Expert Brainstorming for Domain Adaptive Person Re-identification
- 会议: ECCV2020
- 作者:北大数字媒体研究所/Yonghong Tian组
- 代码: github
- Motivation and Contribution
- 为域适应Re-ID任务提出了一种可行的模型集成学习解决方案
multiple expert brainstorming network (MEB-Net), 该模型首先使用了三种不同的深度骨干网络在带标签源域数据上训练,然后在第二阶段中,采用互学习策略学习三个模型在目标域数据的适应。 在第二阶段的互学习中,作者提出了两种互学习损失Mutual identity loss和Mutual triplet loss,每个模型都通过这两个互学习损失进行优化。 - 为了调和不同专家模型的特征分类性能,作者还设计了一种
Authority Regularization来加权每个模型优化时用到的互学习损失。 - 在当时取得了SOTA,性能提升显著,主要使用了
Market-1501 and DukeMTMC-reID两个数据集。
- 为域适应Re-ID任务提出了一种可行的模型集成学习解决方案
-
模型示意图
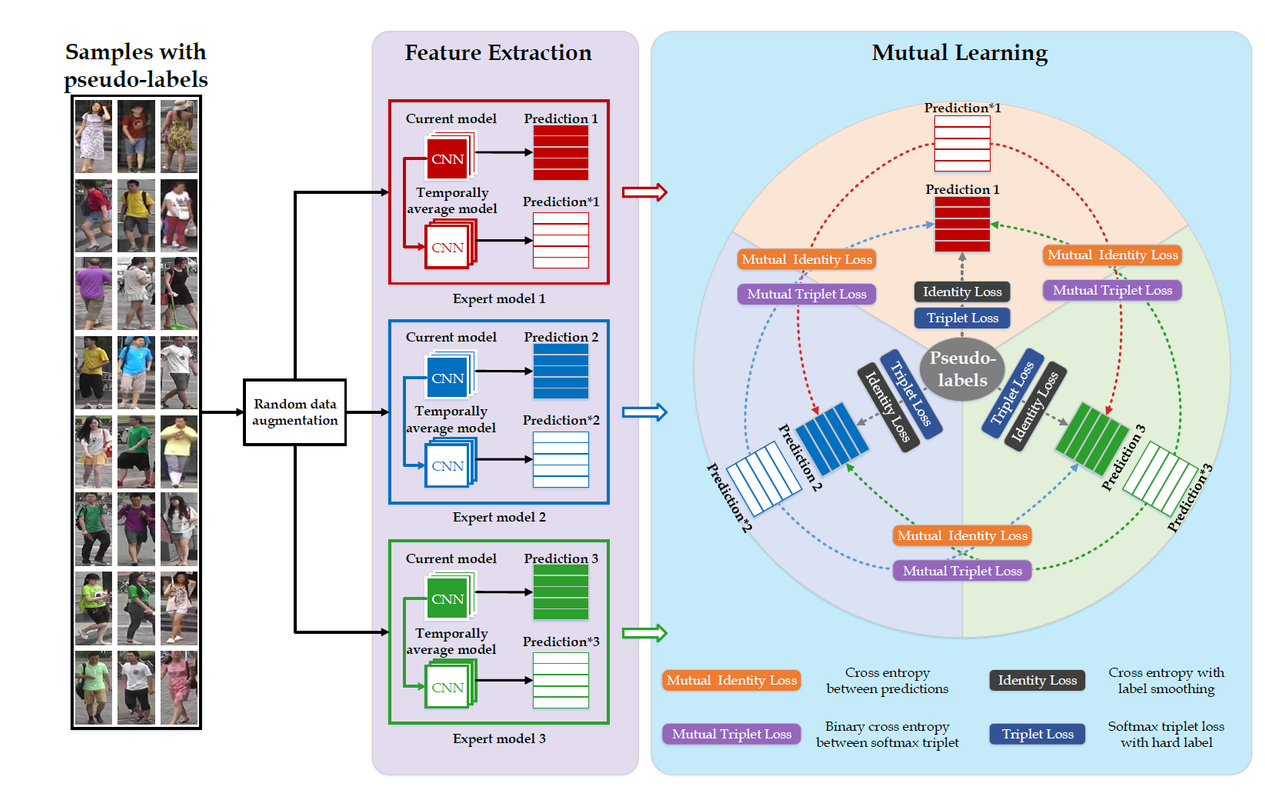
关于源域上的学习使用到了两个损失,行人ID预测的
\[\mathcal{L}_{s, t r i}^{k}=-\frac{1}{N_{s}} \sum_{i=1}^{N_{s}} \log \frac{e^{\left\|f\left(x_{s, i} \mid \theta^{k}\right)-f\left(x_{s, i-} \mid \theta^{k}\right)\right\|}}{e^{\left\|f\left(x_{s, i} \mid \theta^{k}\right)-f\left(x_{s, i+} \mid \theta^{k}\right)\right\|}+e^{\left\|f\left(x_{s, i} \mid \theta^{k}\right)-f\left(x_{s, i-} \mid \theta^{k}\right)\right\|}}\]交叉熵损失(使用了label smoothing技术)$L_{s, id}$和正负样本triple loss$L_{s, tri}$, $s$表示源域。 \(\mathcal{L}_{s, i d}^{k}=\frac{1}{N_{s}} \sum_{i=1}^{N_{s}} \sum_{j=1}^{M_{s}} q_{j} \log p_{j}\left(x_{s, i} \mid \theta^{k}\right)\)这两个损失和在目标域适应阶段使用的损失基本一致,只是标签换成了其它专家模型预测的标签即
Soft Class Labels. 作者在文中说直接使用专家模型比如$\mathcal{M}^{k}$的预测结果作为其它专家模型的标签,有可能传播放大预测的不准确性。 因此作者使用指数移动平均技术EMA(半监督学习一致性正则化)去得到专家模型更加可靠的预测结果(为什么会更加可靠还不太清楚?),有了其他专家模型的预测结果,那么将其作为标签代入上面两个损失计算公式作为模型$\mathcal{M}^{k}$的互学习损失。Authority Regularization就是根据不同模型对目标域数据的分类能力(依据ICC,类之间的距离方差和类内的方差比值)去平衡各个专家模型的损失,因为对于每个其他的专家模型的预测结果,$\mathcal{M}^{k}$都要计算一对互学习损失,那么该正则化就是对不同专家模型的损失乘上一个权重。 - 实验结果
-
Market-1501 and DukeMTMC-reID两个数据集上的结果提升明显
-
消融实验
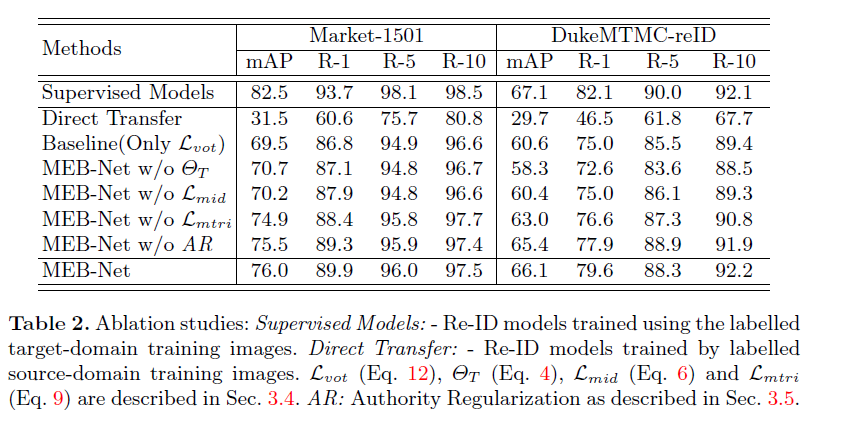
第一行
Supervised Models作者给出了在有监督下的任务的上限,此外AR正则化对模型的提升不是很大,指数移动平均还有ID交叉熵损失对模型的比较大。
-