Domain Adaptation for Object Detection / 域适应目标检测数据集
KITTI
- 下载地址
- 需要注册,进去主页后选择下载
Download left color images of object data set (12 GB).
- 需要注册,进去主页后选择下载
- KITTI是一个自动驾驶的数据集,刚才下载的数据集里有7481张训练集图片和7518张测试集图片, 只能使用训练集训练模型,但是不能用来测试模型。因此只能下载到训练集的标签。
CityScapes
- CityScapes是一个是一个语义分割数据集,一共5000张图片,包括2975张训练图片、500张验证图片5和1525张测试图,每张图片大小都是1024x2048。每张图片都有像素级的标注,经过转换后,可以用于目标检测任务。该数据集都是正常天气下不同城市的市区场景,目标物体主要是行人、车辆等。
Foggy Cityscapes
下载地址
Foggy Cityscapes是在Cityscapes数据集基础上添加人工合成的雾制作而成,因而标注信息和原Cityscapes数据集完全相同。由于每张图像都添加
三种层级的雾,因此该数据集的图像数量是Cityscapes的三倍。
BDD 100K
SIM10K
- 下载地址
- SIM10K数据集是通过
Grand Theft Auto V (GTA5)游戏引擎合成的人造数据集,一共10000张图片。车辆的目标框一共 含有58701个,在域适应目标检测任务中,该数据集被当做是源域训练集source train。对应的目标域训练集target train是Cityscapes的训练集(2975张图像), 模型性能的测试集是cityscapes的验证集(500张图像)。因为cityscapes数据集中的实例标签含有8种,因此我们 需要抽取出其中car的类别实例。
Clipart1K, Watercolor2k , Comic2k
Clipart数据集的类别和 PASCAL VOC数据集一样有20个类别,共有1000张图片,3165个实例,数据集采用了VOC存储格式,大概几十M,主要是一些
漫画性质的图片。
Watercolor数据有6个类别,共有2000张图片,3315个实例,数据集采用了VOC存储格式,大概3个G左右,主要是艺术画
Comic2k数据有6个类别,共有2000张图片, 6389个实例,数据集采用了VOC存储格式.
PASCAL VOC
这个数据集一般用作source train数据,包含了20个类别,在域适应任务训练中使用VOC2007和VOC2012的train_val共16551张图像。
1. Exploring Categorical Regularization for Domain Adaptive Object Detection
Motivation and Contribution
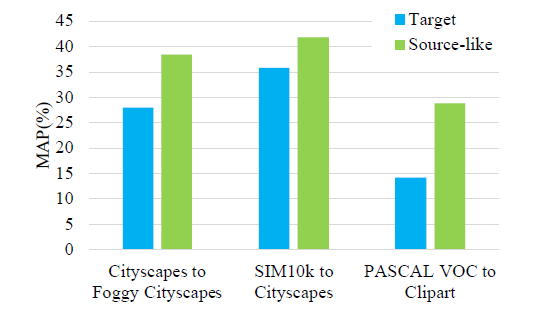
2. Unbiased Mean Teacher for Cross-domain Object Detection
Motivation and Contribution
- 普通的
mean teach model在域适应任务中有较强的偏置问题,严重影响了域适应模型的性能,作者使用具体的实验结果如下来引入自己的motivation- 具体来说对于
teacher网络对于source data可以产生precise的预测标签, 而对于target data产生的标签错误率较高,导致student网络的学习低效。 student网络同样也存在相似的偏置问题
- 具体来说对于
- 基于以上观察作者提出了三种方法
- 为了提高
teacher网络预测target data的标签准确度,作者使用了CycleGAN对target data进行了风格转换使其看起来更像是source data,这样就 提高了对target data的预测准确性 (数据本身是不变的,但是预测的难度缺降低了)。相反,studen网络却输入了正常的target data进行训练。这样做的 效果就是输入student网络预测困难的target data,却赋予了其更加准确的标签(预测不那么困难的target data),从而提高学生的学习潜力。 - 为了减少
student网络的偏置,作者同样使用了CycleGAN对source data进行转换使其看起来更像target data,作为网络的输入,这样就使得网络明明 输入的是更加符合target domain的数据,理论上会由于domain gap得到错误的结果,但是却在正确的标签指引下扭转了domain gap带来的影响,使得网络域适应 能力更强。 - 最后作者为了网络更好的教学,使用置信度筛选出更适合知识蒸馏学习的
target data去实施教学.
- 为了提高
方法介绍
明白了作者的大致思路之后,模型就比较易懂了
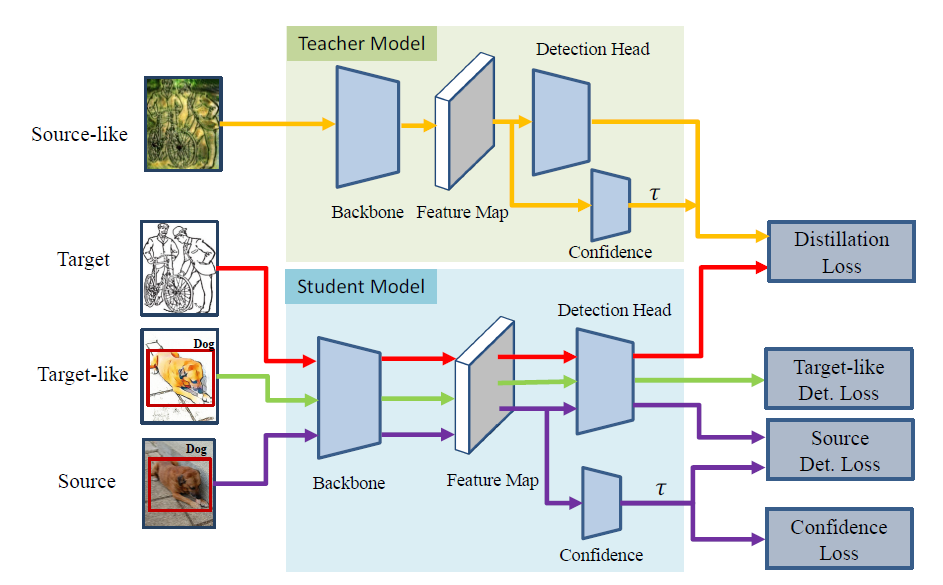
首先使用 source data 训练一个网络作为 teacher网络和student的共同的初始化,然后执行跨域的知识蒸馏。
在教学过程中,teacher网络的输入是转换后的target data,以产生相对更加准确的pseduo labels, teacher网络的参数是student网络指数移动平均的
结果。pseduo labels作为输入student网络的原生target data的标签进行学习,损失为图上的Distillation Loss
student网络的输入包括三个来源:原生的target data、原生的source data、转换后的target data,这是把跨域的数据增强给玩明白了!对应的损失为
Distillation Loss、Source Det Loss、 Target-like Det Loss。
此外就是应用了置信度预测网络Confidence,来筛选更合适的教学数据,损失为Confidence Loss.
实验
- SOTA 比较
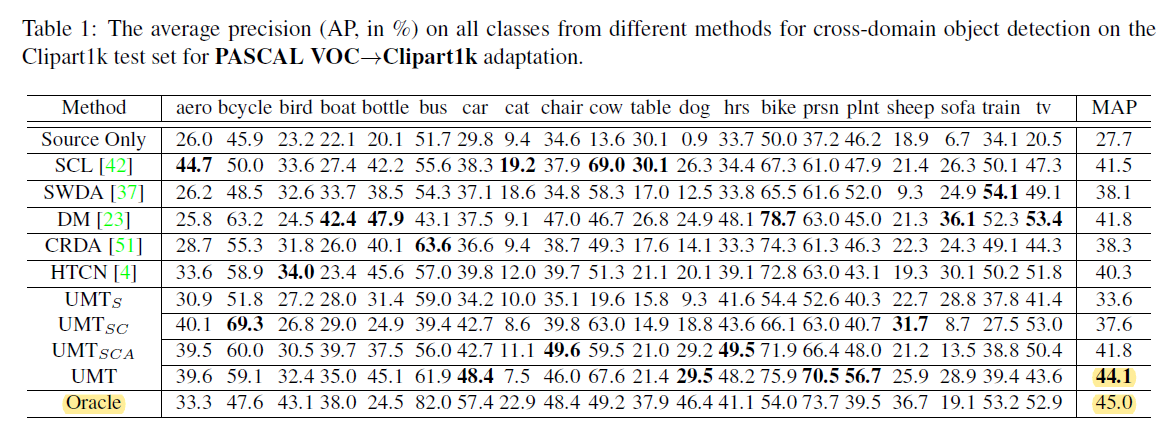
PASCAL VOC 适应 Clipart1k
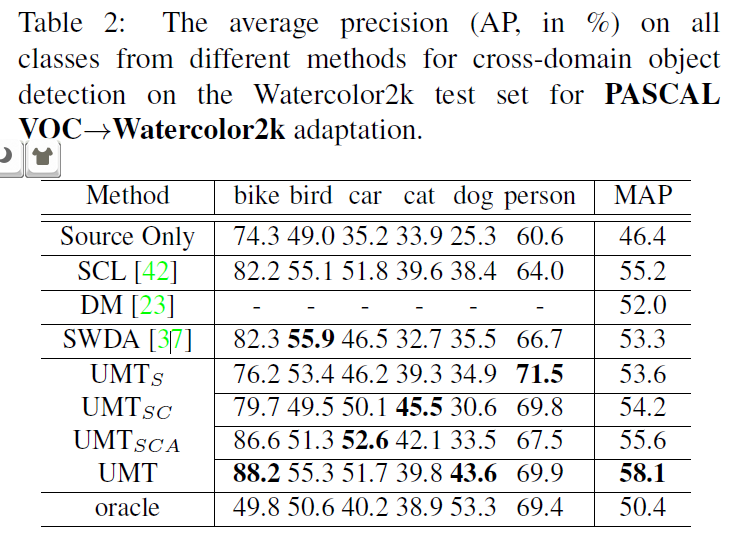
PASCAL VOC 适应 Watercolor2k
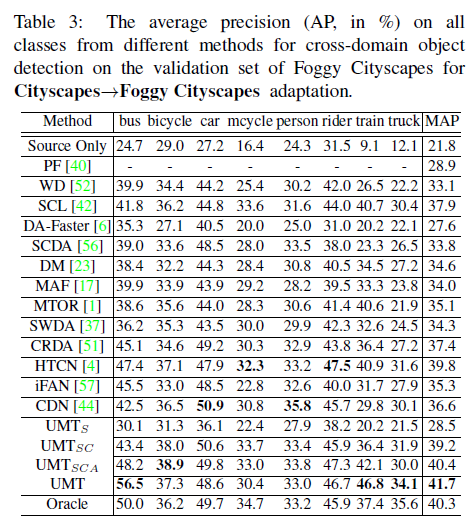
Cityscapes 适应 Foggy Cityscapes